

APSP

APSP
Prerequisites
- morphine 先来一剂Green Day 牌吗啡!
在结尾处,准备总结一下实验的一些基本环境配置和有用链接以及FAQ留个之后看到这个网页以及遇到问题的人,所以如果是有问题需要解决可以先看看结尾。保证可以复现乐 : ) - Cmake 熟悉cmake 的常见函数或命令以及了解下makefile 的原理 有点搞笑 我们的这个prefix 的路径似乎不能使用 ~ 而必须使用绝对路径
- OpenMPOpenMP
- 首先,我们知道对于floyd算法的三层for循环中 ,最外层k 是无法并行化的,因为每一个k的路径比较依赖于已有的路径,需要顺序进行更新,但是内层i,j循环在src dest一定时,k 可以按照任何顺序选取所以是可并行的。因此private(i,j).
- OpenMP 原理 就是启用多线程,具体运行的时候可以跑在多核上,并行运算。底层就是pthread 实现的
- 平衡负载,我采用的是dynamic ,不过可以多试试看看,static guide 都可以尝试,默认的也可以,感觉每次迭代的计算量似乎是随机的但是总体是均匀的 感觉static 应该就可以,dynamic 还是用在计算量会增加的比较好
- 线程数的设置,过多会增大合并开销,同时还存在内存分配问题,降低效率,数量过少会导致并行度不够,根据我的猜想,看CUDA简介的经验,使用一个和迭代数以及某些硬件属性数的倍数或者因子书。32 64 之类的。问题不大,实践是检验真理的唯一方式,多试试就可以了,试了再来补充。
- 编译器优化猜想,首先就是编译器可能帮我做了loop unrolling ,估计是fully peel the loop有可能。 然后就是寻址方式,依照CSAPP 上的,对于一个定长二维数组,确定一些基指针,然后使用定长进行改变。减少访存。然后就是使用局部变量来保存一些结果减少内存访问。同时也可能使用了一些向量化操作(AVX指令等等)。常熟计算(constant propgation)编译时计算,也就是constexpr。将小函数进行内联,但是本例中似乎不存在。

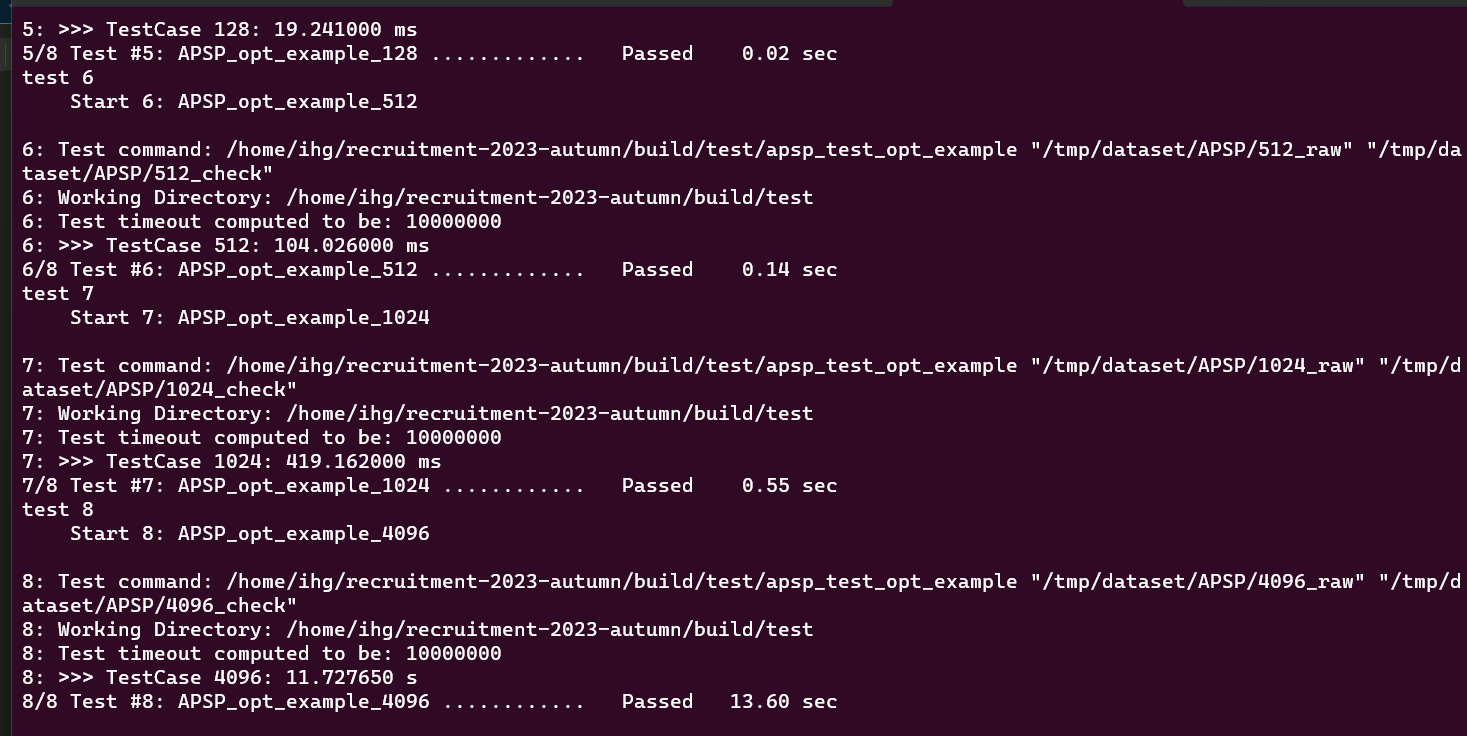
- 这个只是使用了最基本的for 内层循环并行,和负载动态分配
- 这个比较客观,在第一次基础上使用了omp的 simd优化最内层循环。4096的加速比接近baseline的100倍,当然我这里选择的是64线程数 使用128线程差距不大。不过我个人感觉没有找到更好的方法进行线程数的调参。不知道有没有除了顺序试错外更高效准确的判断方法,还待我考察,欢迎学长指教。
- AVX参考 avx优化
- 使用的是AVX512,用一个 mask store 来实现比较运算。
- morphine 先来一剂Green Day 牌吗啡!
BFW (算法优化——Blocked Floyd Algorithm
- 查找了一下资料,似乎这个可以提高数据的局部性,当然需要设置好所分的矩阵块的大小,使处理一个数据块的工作集内存大概等于 L2 cache .但是感觉实现这个算法本身加速比不是很明显,然后分块的话额外内存开销较多。(还有就是懒:) 所以就没有进行应用。
Pthread接口实现多线程
- 可以,今天用pthread把内层两个循环并行处理了一下,加速比大概500倍。跑4096的图用了13s左右,我自己设置的线程数为这个时候文件夹还没改名,当然但就算法运行时间大概11s左右
- 使用局部变量优化了一下 大概8s 多一点
- 可以,今天用pthread把内层两个循环并行处理了一下,加速比大概500倍。跑4096的图用了13s左右,我自己设置的线程数为
AVX512改写内层循环 速度大概2s提升 4倍
- 不过这里我有一个问题,就是理论上直接来看,应该会提升16倍,实际上只提升4倍左右,我自己猜测的原因是缓存问题,由于嵌套循环,存取的时候空间局部性不是很好,等后面有时间profile 一下。
- 循环展开64 后 线程数 90 接近突破2s
- 记录下首次突破 2s 作了128的循环展开 然后将线程数调到了100后续测试感觉 64循环展开 和 128差不多了。感觉实际上我们的128循环展开可能效果还差一点,因为使每一个线程的工作负载变大了。
- 感觉实在找不到什么可以优化的地方了(在我目前所学的知识范围内)大概在1.85s左右 悲。有一个分块floyd算法,改善局部性,感觉就单独实现而言,确实可以通过减少工作集内存的范围来提高空间局部性。但是因为涉及到要重写pthread,感觉反而会增加线程创建的开销。因为需要不断迭代子方块,然后进行pthread_create和pthread_join。
- 本来想学一学使用 vtune 来剖析一下,似乎集群没有装,然后数据scp 命令没有使用权限,所以没有profile很多对性能的猜测都是自己的直觉 乐!
- 至于GPU的算法,看了一下,似乎没有看到集群有装CUDA,所以没打算写,看后面有没有时间参考下资料看一看。
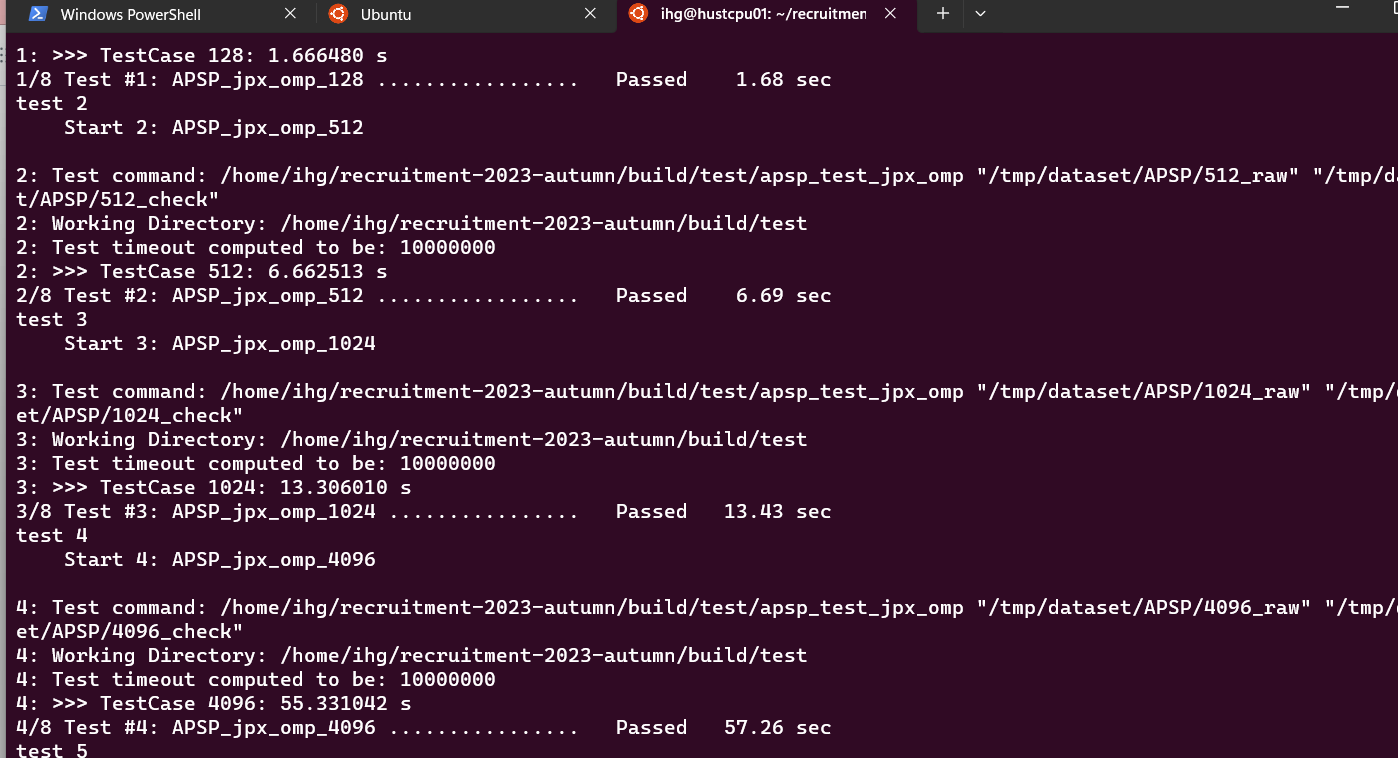
 这个时候文件夹还没改名,当然但就算法运行时间大概11s左右
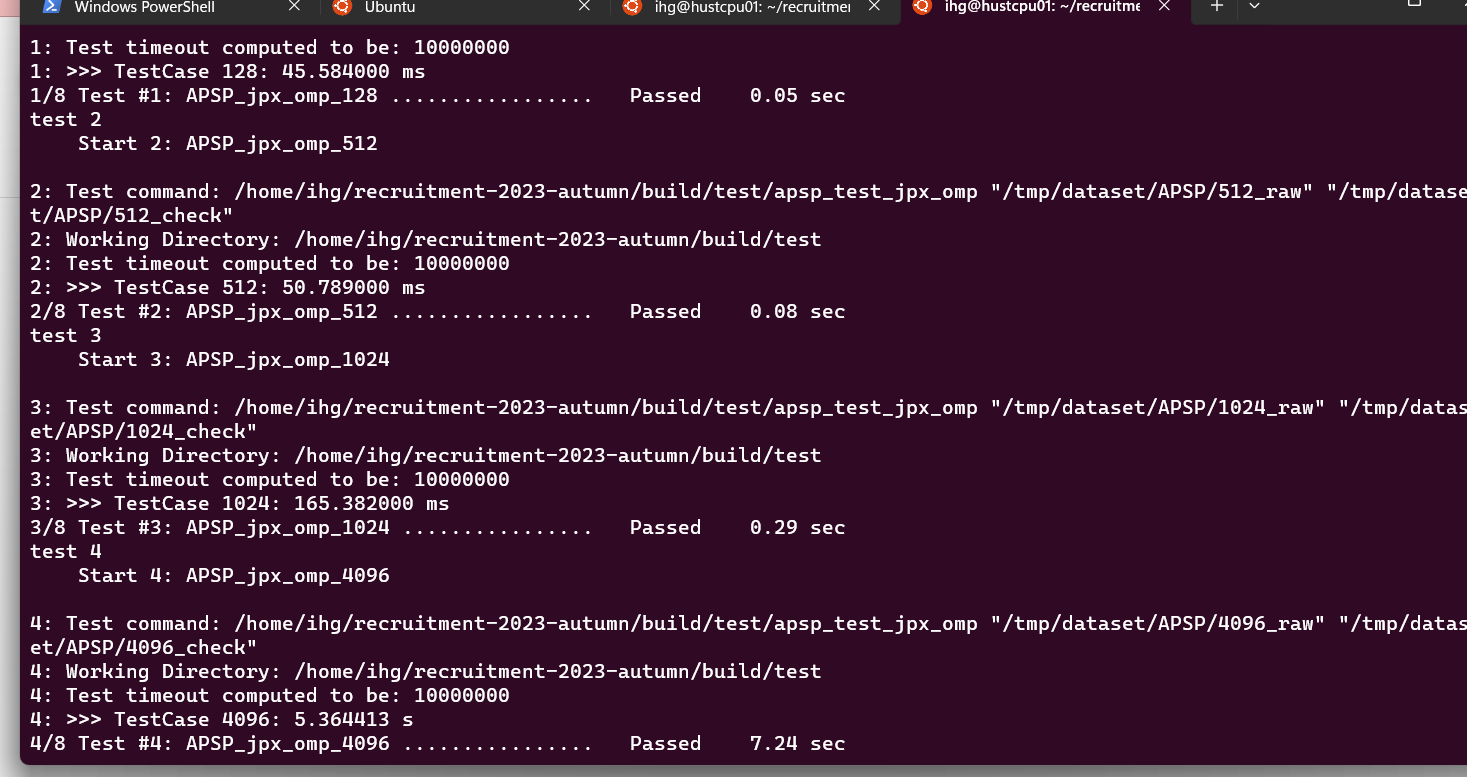
这个时候文件夹还没改名,当然但就算法运行时间大概11s左右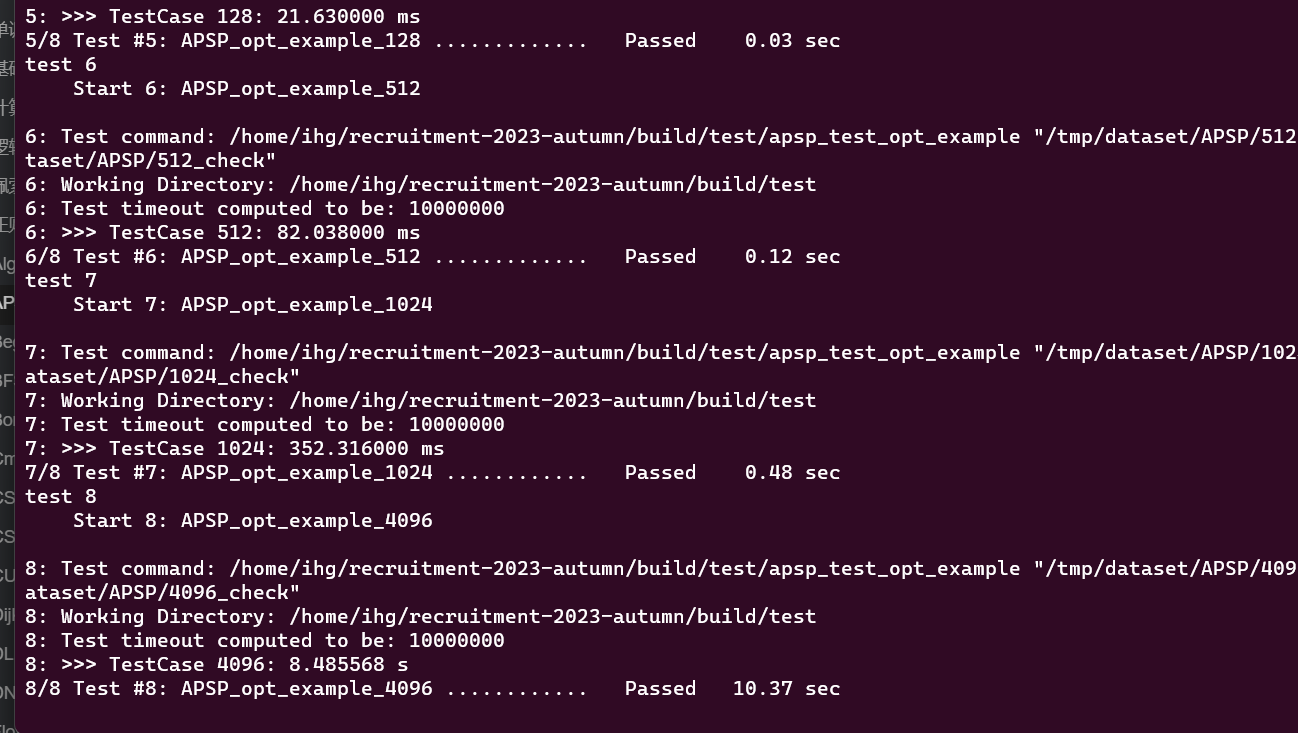
 循环展开64 后 线程数 90 接近突破2s
循环展开64 后 线程数 90 接近突破2s 后续测试感觉 64循环展开 和 128差不多了。感觉实际上我们的128循环展开可能效果还差一点,因为使每一个线程的工作负载变大了。
后续测试感觉 64循环展开 和 128差不多了。感觉实际上我们的128循环展开可能效果还差一点,因为使每一个线程的工作负载变大了。 大概在1.85s左右 悲。有一个分块floyd算法,改善局部性,感觉就单独实现而言,确实可以通过减少工作集内存的范围来提高空间局部性。但是因为涉及到要重写pthread,感觉反而会增加线程创建的开销。因为需要不断迭代子方块,然后进行pthread_create和pthread_join。
大概在1.85s左右 悲。有一个分块floyd算法,改善局部性,感觉就单独实现而言,确实可以通过减少工作集内存的范围来提高空间局部性。但是因为涉及到要重写pthread,感觉反而会增加线程创建的开销。因为需要不断迭代子方块,然后进行pthread_create和pthread_join。- Post title:APSP
- Post author:Winter
- Create time:2023-12-05 16:33:50
- Post link:https://spikeihg.github.io/2023/12/05/APSP/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.