

DL

Deep learning premier
志を受け継ぎ世界と戦う
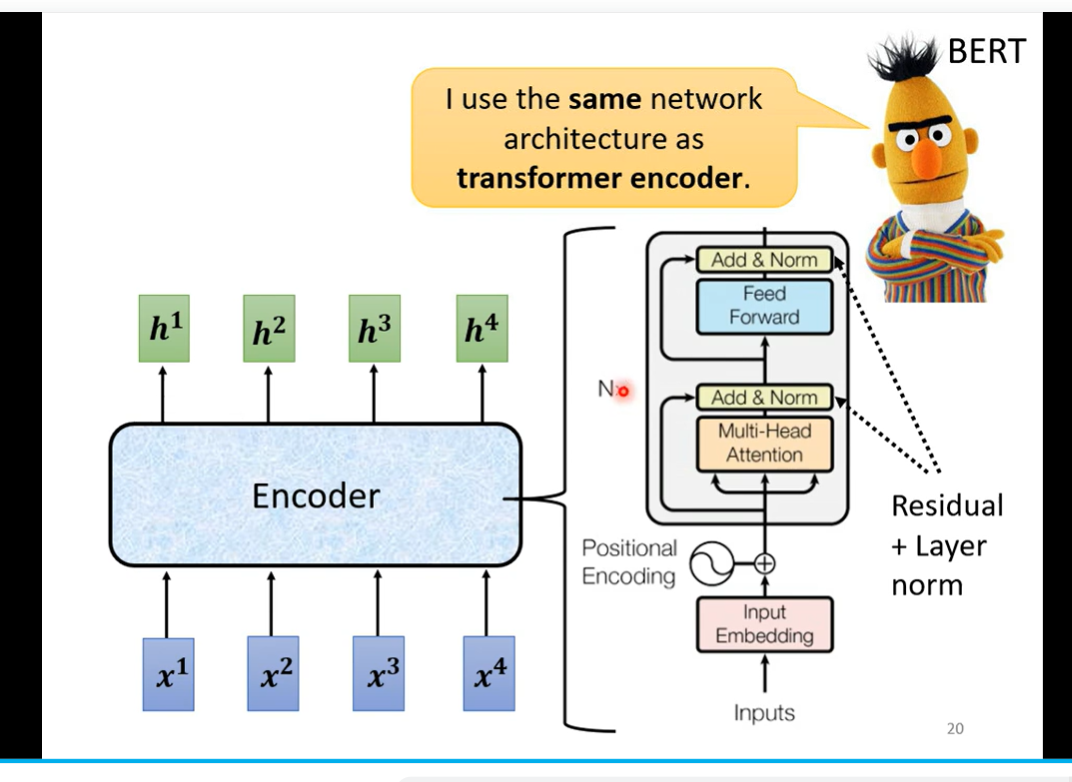
Transformer
transformer是什么?变形金刚!!! 好吧transformer 是用来解决seq2seq的一个模型。 seq2seq是一种模式,一些常见的情形:翻译,听译,语音辨识,听译 男泵 万恶之源 硬train一发 chatbot 之类的也是
BOS
NLP QA模式 问题回答的一种模式
multi-label 就是每一个输入对象可能身上有多个标签
transformer 就是求解s2s的一个模型 encoder 和 decoder
residual connection 这个是与self attention 不一样的地方把input 和 output加起来
为什么能够应对seq2seq的情况
输入有两个部分 一部分来则于自己之前的输出
masked -attention 为什么需要
单纯看自己的输入作为输出的时候不可能停止下来,机,器,学。习。惯…… 首先我们需要准备以恶搞special toke as end(断) 所以原理就是让机器学习断,在该停止时候最大的概率输出end
上面是对于AT NAT是同时产生所有的输出 解决停止问题 有两个,第一个单独训练一个classifier来判断长度,方法二,传入很多begin token.忽略end 后的 输出 NAT 更好的并行化,可以控制长度 但是效果很难达到AT multi-modality
decoder 和 encoder的连接依靠一个叫做 cross-attention 的操作完成的就是 decoder 产生的向量q然后对每一个encoder的output k做kq,然后得到的新的v作为input丢到fc进行之后操作
train的时候采用分类的视角 计算向量之间的cross-entrophy 并且在训练情况下,我们给decoder的是正确的答案 就是一个监督 tearcher forcing
训练的一些 tips copy mechanism 例如chat-bot 将一些从来没有见过的词汇 直接进行复制 例如做摘要的时候 pointer network
TTS 语音合成 guide attention 就是规定 attention的顺序 有固定的过程 需要提前分享任务的特征monotonic attention
观察确定 我们的encoder 就是输出简单的数据 作为中间向量
beam search greedy path可能存在问题 局部最优不代表全局最优 类似于老师讲的王者问题 加入随机 decoder加一点 noise
BLEU score 用来检测inference 的指标但是训练的时候使用的是cross -entrophy 这两个没有关联的,没有相关性的blet score无法微分 一种策略使用 rl reinforcing learning reward与 agent来硬train一发
在训练的时候加入一些错误的情况,scheduled sampling 也很直觉啊,面对错误的时候得到正确的这样学习应对错误的能力
self-attention
- q,k 矩阵学习 multi-head 就是分出多个 q 矩阵 然后得到bi,j 然后再处理成一个 positional embding , hand-crafted 目前的 目前是一个全新的领域 也可以学习。 self-attention 之间是没有位置关系的,然后q k 也不一定需要包含整个窗口
Batch normalization
layer norm 是对同一个feature(sample)不同的dim 进行计算 mean和 deviation 而 batch norm 是对所有不同的feature 的同一个dim 进行处理

- position coding 位置资讯
实际设计中还可以在顺序上进行变换 上述大概就是encode 结构
decoder
- bos (begin special token)特殊的符号 标记开始
- masked self- attention 和通常的attention 有一些区别
- 为什么 因为decoder是一个一个产生的 在产生前面的输出时,后面的右边的输出还没有产生 无法考虑
- autoregressive
- 自己不断运作,输出再次作为输入然后一直运行 存在停止的问题 方法就是设置另一个token 有时候与begin其实是同一个 实际实现可能是一个one-hot 向量,end也是自己产生的男泵
- NAT non-autoregressive
pytorch
总体流程就是,先定义我们的数据, dataset可以理解为存储我们的数据,feature 和 label ,然后dataloader 以我们想要的方式加载数据,自定义操作,包括batch ,还有 transform 等等。
然后就是定义 目标函数 loss ,以及一个优化器 optimizer ,有了之后定义 响应的train 和 test 函数 ,最后还有对模型的保存以及调用 和实际运用。
tensor (array)统一的却应用广泛的数据结构 ,就是一个高维数组,最外面的维度为dim=0 注意顺序 然后基本上有外面可能用到的所有操作,只需要用时自己去找api 查资料就可以了。
dataloader & dataset
- torch.utils.data.dataset torch.utils.data.dataloader 两个基本的提供的模块除此之外很多专门领域的domain-specified 的库都有自己的相关的。 注意一般来说,然后从我们的视角来看,就是一个数组 索引得到feature and label 同时得到。a,b=dataset[index]大概这样,然后label 一般存在一个csv文件(逗号分隔文件里面)然后就自定义__init—— len getitem三个函数 init 的时候传入的 是一个annotation_file 和 dir 两个都是字符串,然后两个transform 函数一个transform 一个 target_transform
- pandas 是一个数据处理 比如读取csv_file 之类 os 就是处理字符串之类的
- dataloader 的每一次迭代返回两个tensor 对应feature和label
- transform modify featu target_transform modify label
- 常见的totensor 就是实现normalize 并且使得元素在0-1 之间。 vector lambda就是自定义操作
build the network
- torch.nn 所有存在的neuralnet的父类。 module其实就可以理解为layer 一个神经网络就可以理解为 a module itself that consists of other modules(layers) from torch import nn
- 第一步先check一下可不可以用硬件加速
- 然后继承 nn.Module 然后定义两个东西 init 和 forward方法
- 我们来break down and see every module拆解看看每一层
- flatten 在图形里面用来将一个image 矩阵转换为一个一维数组
- linear 层就是进行一个线性转换 我们需要预先输入一个weigth 和 bias参数 然后对feature 进行变换
- 这里一个额外的补充知识点 就是call 特殊方法可以实现将类作为i函数调用 这就是为什么我们可以调用model,将数据作为参数输入进去 linear其实就是继承了nn.Module
- 妈的,我逐渐反应过来了,linear层里面的bias ,weight都是默认输出话,随机的其实,因为这个是我们要学习的参数,所以随机初始化就可以了。不需要什么预置输入
- 这里提前所以个东西 Relu 可以解决sigmoid 和tanh的过饱和问题缓解过拟合问题 也是目前默认激活函数
- flatten默认改变的是最里面的层 没有改变channel 和batchsize
- nn.sequential 就是一个layer的顺序容器 其实经过一个sequential 我们就可以发现输出了y 相当于fully connected network 啊男泵
- nn.softmax 如果分类还需要过一层 注意通常要指定softmax操作的维度
- parameter() named_parameters()这两个方法可以让神经网络追踪传入的参数哦从而进行学习
- 终于逐渐理解了
automatic differentiation
关于tensor 的矩阵乘法 要了解到tensor最后面的参数一定是列向量 这个有点差异
parameter 就是我们需要进行optimize的 weight bias 都是。对于这些参数,我们需要优化,所以我们需要预先设定require_gradient ,默认是false
然后调用Function 类,这个在每一个tensort 的 grad.fn 属性里存这一个指针,表示该tensor所使用的反向传播计算时的函数
在tensor的grad 里面维护的是计算得到的梯度值
所以现在我们可以这样理解forward就是利用model来进行计算,backword就是train,所以后面我们训练完成的时候,需要使用 with torch.no_grad()的方法
现在来审视这个 DAG leaves is input tensor root is output tensor and the node is function !!!!!
- 然后实际的是实现中我们使用了雅各布矩阵直接做矩阵乘法!!!
Optimizing model
- 在上面的过程我们可以明白了,forward其实就是调用预测时候的算法,所以实际上就是直接调用我们的init 里面的层 然后返回就可以了
- 在这里我们区分一下parameter ,就是在里面起作用的东西,hyperparameter 更像是一些设置配置参数 例如 learning rate ,batch size ,number of epochs
- loss function 。 对于回归问题我们通常使用的是MSELoss, 对于classification 我们通常使用的 是 negative log likelihood NLLLoss 然后nn.crossentropyloss 就是 logsoftmax和NLLLoss的结合
- 我们前面学的adam rmsprop sgd 其实就是不同的optimizer 也就是minimize的时候使用的算法
- 实际运行的时候有三个步骤
- 第一步就是先显式置零,同时自动累计grad,以免没重复加
- 第二步就是运行反向传播算法
- 第三步 调用.step()方法进行更新
- 最后就是进行实现两个loop 一个train loop 一个 test loop
- Save and load the model
- 组后要进行保存和加载的化调用响应的方法即可 ,然后注意两个东西就是.eavl() 模式的切换,记住这个是避免dropout和batch normalization 的一个东西
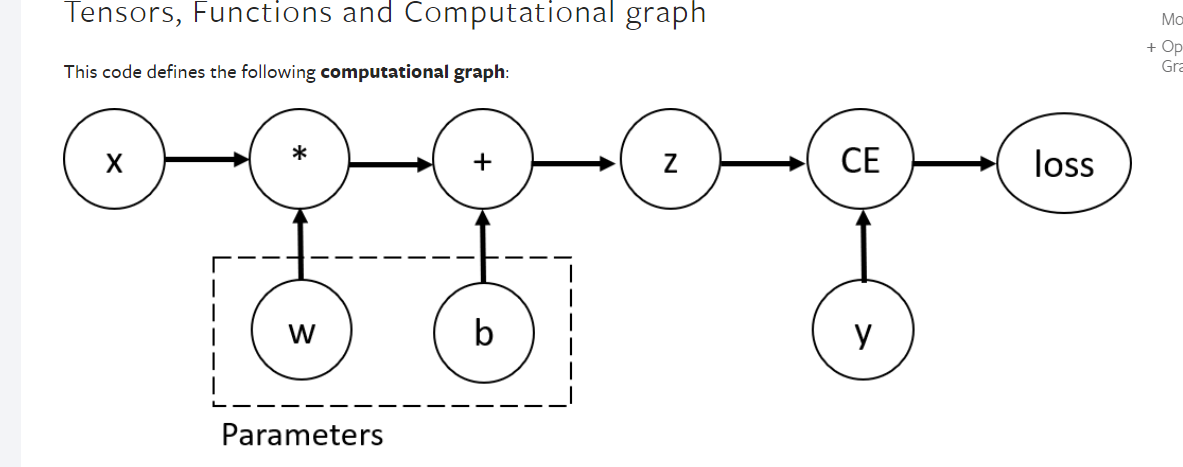
computational graph
反向传播
前向传播和反向传播 forward and backward torch的抽象 forward 可以理解为求值 从input 到output 从leaf到root 反向传播就是求误差,根据链式法则求取偏导然后更新参数进行optimize。
torch的实际实现过程
根据我们对neuralnet 的定义 一个sequential 里面有很多layer,然后forward就是调用这个module ,在进行forward pass的时候会进行两件事情,第一件事就是按照要求计算得到output tensor第二件事就是建立其DAG,每个结点就是对应的求导函数,在后续的backward pass中调用进行求导
what you run is what you differentiate.
- tensor 需要保存,用来求导
- 对于数学上不可求导的函数或者是未定义情况有指定的数学方式来处理
- 先要阻止gradient 可以更改text manager mode 以及.eval(),同时要想控制子图subgraph的性质 可以对单个tensor 调用 require_grad
- torch.nn 中parameter默认要求导,中间变量都会求导
- 现在终于懂了
- lossfunction 进行 backward()相当宇求梯度然后得到grad值,optimizer 则是根据不同的类型操作 grad 进行更新所有 parameter .step()就是进行一步 。 .zero_grad()就是重置tensor
梯度消失和爆炸 的原因
我们在计算梯度的时候采用的是反向传播求取雅各布矩阵,由于很多hidden layer都会采用一些激活函数对于sigmoid而言,其倒数最大值为0.25 如果乘以w 后得到的积仍然小于1 如果很多小于1累计起来可能造成靠近输入层的参数更新极为缓慢,当然输出层的影响较小,爆炸则是产生NaN 或者不稳定。
transformer is all you need
- 正向的 rnn 。 双向的rnn 可以正反同时读取我们的,
- LSTM 关键四个们 标量也是用来学习的 每个单元可以用来替代之前的neuron 然后只是输入需要四倍,因为三个们和一个输入 。使用的是sigmoid 函数表示打开的程度。实际的模型还会在输入中参考中间步骤的输入
- BPTT learning train 的 方法。考虑时间的关系。
- train的问题 error surface存在很平坦到很陡峭的分界限,所以存在参数的抖动。 clipping 解决方案,就是为gradient 做一个上界,如果超过就直接等于。
- Post title:DL
- Post author:Winter
- Create time:2023-11-23 19:24:27
- Post link:https://spikeihg.github.io/2023/11/23/DL/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.