

CUDA

CUDA&Algorithm
Prelace
希望通过CUDA走进计算的前言,并且加深我对计算机体系结构的认知。同时从另一条路走进我们的machine learning 与 deep learning.同时也在这里写下一些算法的学习知识。
F&Q
内存布局具体硬件实现忘了,忘了栈实际上是在cache还是memory里
nvidia-smi 才是查看设别的指令 nvidia-smi -q 不错
nvprof 已经弃用了 ncu(nsight-compute) 现在是profiler
nsight-compute 需要 全局安装 sudo apt install -y 选项issue
driver 是一个硬件用来显示的 tookit就是一个集合 有些下载method可以同时下载适配的 driver 总结就是除了会安装还要学会卸载
These instructions must be used if you are installing in a WSL environment. Do not use the Ubuntu instructions in this case; it is important to not install the
cuda-driverspackages within the WSL environment. 乐死Installation using RPM or Debian packages interfaces with your system’s package management system. When using RPM or Debian local repo installers, the downloaded package contains a repository snapshot stored on the local filesystem in /var/. Such a package only informs the package manager where to find the actual installation packages, but will not install them.
If the online network repository is enabled, RPM or Debian packages will be automatically downloaded at installation time using the package manager: apt-get, dnf, yum, or zypper.
安装是很复杂的 wsl有单独的教程 然后就是 有 post-installation mandatory actions !!
The
PATHvariable needs to includeexport PATH=/usr/local/cuda-12./bin${PATH:+:${PATH}}. Nsight Compute has moved to/opt/nvidia/nsight-compute/only in rpm/deb installation method. When using.runinstaller it is still located under/usr/local/cuda-12.2/.记住这个路径问题 在opt里面妈妈我终于解决这个问题了 就是我在安装后没有设置环境变量 啊啊啊啊啊啊 男泵
开始在vscode 里面进行配置 nsight debug
ctrl + space
命令面板很好用目前看来 ctrl shift + p
我修改了提示 ctrl + t + s 好有用啊 还有就是控制面板太好用了有很多提示键 然后 task 也可以在里面选择生成
- [launch attach& launch.json entry](Debugging in Visual Studio Code )
dropdown configuration 就是下落的可以滑动的竖直设置栏
预定义变量
最新发现 ctrl alt n code runner 似乎无所不能 但是不能调试只是
program 就是 要debug的文件
注意这个launch 是调试 要先生成可执行文件 也就是task 先配置的是task 然后是 launch.json
重点出现了 发现可能的解决方案 就是prelaunch task 原来之前的是task 在debug后运行或者至少同时
原来c_cpp_pr 是C++插件的配置文件不会影响
Heterogeneous Computing
host指cpu,host codes run in CPU ,CPU code is responsible for managing the code and environment and device code running in GPUs.
common GPU architectur GeForce Tesla and Fermi in Tesla Tesla professional hpc. GeForce consumer GPUs
two metrics to discribe the GPU compute capability .the core no. and the memory
互补的 CPU 逻辑复杂 擅长分支预测控制流切换 GPU 擅长大量数据 简单控制 并行计算 Threads of CPU are heavyweighted 上下文切换开销大。 GPU就是相对轻量级 的
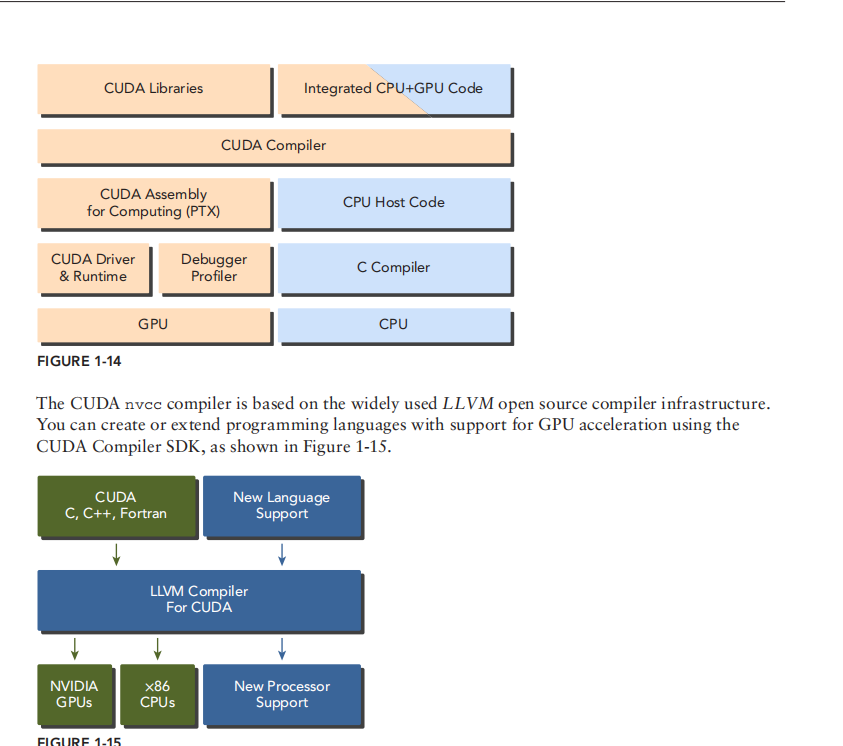
CUDA driver API and CUDA runtime API 我们一般使用 runtime API cuda codes 包含两个部分 一个是host code 另一个是device code
kernels 就是device code 里的并行函数由 nvcc 编译 nvcc 会区分host code and device code 然后就是完全分开执行 good

hello from GPU GPU program structure 5 steps 分配显存 加载数据 invoke kernel 返回数据 销毁显存
locality temporal locality and spatial locality 这是编写cpu程序注意的 而GPU 将存储架构和线程结构都展示给程序员
three key abstractions 三个关键抽象对于GPU 1. hierarchy of thread groups 2. hierarchy of memory 3. barrier synchronization
- nvcc 支持的文件后缀 .c 普通的是可以编译的
programming model 其实就是 抽象 通过使用compiler and library & OS 对hardware architecture 的抽象 scalability 可拓展性
Host CPU and its memory ; Device : GPUs and its memory eg h_ for host m; d_ for device space
Kernel 即跑在GPU 的codes我们可以看作是一个普通函数 实际上 GPU将其分配在多个线程上同时运行 ,当kernel运行后控制会立马交还给cpu以开始其他工作 异步工作。serial code 串行码 complemented by parallel code
1
2
3
4
5
6
7
8
9
10/* Memory management */
malloc(); -> cudaMalloc();
memcpy(); -> cudaMemcpy();
cudaMemset();
cudaFree(); // all in device memory which is seperated from host memery!!
// the signature of the func
cudaError_t cudaMalloc(void**devPtr,size_t size);// the pointer is returned in the devPtr
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count,cudaMemcpyKind kind ) // the kind takes one of the following types cudaMemcpyHostToHost --HostToDevice --Dev2Dev D2H this func 是同步的 host 会阻塞知道完成
// cudaError_t enumerated type include cudaSuccess .eg
char*cudaGetErrorString(cudaError_t error);Global memory and shared memory in device just like memory and cache in CPU 前面的分配的函数都是在global memory 里面就像我们的malloc一样 目前我们所知道的由于这样内存分类 对应的指针是不能类型转换的,只能用cudaMemcpy来完成转移 后期由unified memory
- 通常而言 grid是二维 block是三维 blockDim gridDim dim3 type 没有初始化的filed自动为1
P88 warp执行模型 32 个thread 硬件层面都会变成 warp 然后分散在SM上执行 之所以可以是主要是内存资源决定的 32 cores是共享的 前面说到多个warp scheduler 调度将warp的一个指令放到16core的一个组合上运行 其中register file 决定了warp 数量 shared memory 决定sm的block数量 然后warp切换上下文没有开销 都是data分割的
- warp 注意4 这个数字是由架构中每个SM的scheduler决定的 stall warp eligible warp 因此我们要最大化active warps
divergence 会执行所有分支 我们将分支按warp 划分
latency hiding
类似于CPU的调度 latency就是时间 一般用clock cycle 计算大小- P91 有趣的排队理论 就是需要同时并行的操作数=延迟(cycle)*预期throughput throughput 与 bandwidth used interchangably bandwidth refer to as peak data transfer per time unit throughput refer to as any operations rate metrics都是throughput单位 ops per cycle per SM 也可以进一步用warps表示也就是/32 so the underlying thing of latency hidding is that you should increase the parallesiem to move like sequential ops without waiting
latency hidding 总体而言需要更多的并行操作也就是需要更多的active warps 但是这个数量又是由memory and register 限制的所以configuration 很重要
有趣的建议
一些使用CUDA 的建议
太大的block size 会使每个thread硬件资源很少 太小的 block size warp 数量太少
GPU ARCH
- The GPU architecture is built around a scalable array of Streaming Multiprocessors (SM). GPU hardware parallelism is achieved through the replication of this architectural building block.
- P 68我们先可以把SM看作一个比较强的硬件 一个grid 对应一个 kernel 一个grid的block可以分配到多个 SMs 然后一个SM 可以有多个block 也可能来自不同的grid(kernel 并发)每一个线程都具有流水线
- SIMT warp为一个基本管理 thread warp中每一个线程的内存与寄存器与计算资源都是独立的 SM将 block划分为warps 所以最好为32的倍数
- Even though all threads in a warp start together at the same program address, it is possible for individual threads to have different behavior. SIMT enables you to write thread-level
- 一个block只能安排在一个SMs!!!记住知道执行结束都在一个SMs 同样的一个SM可以同时有多个block
- 一个grid其实就是整个device了只是支持kernel的并行操纵 然后有个SM商店 shared memory 按照block划分 register 几万个按照thread划分因此 一个block间的thread可以shared mem 交流 While all threads in a thread block run logically in parallel, not all threads can execute physically at the same time. As a result, different threads in a thread block may make progress at a different pace.同一个block中的thread以warp执行 所以实际没有物理并行 这里可能会在 shared mem访存时出现竞争 CUDA提供了block内部的同步函数 但是多个block 之间没有提供同步函数
- 一个core通常有一个整数ALU和浮点ALU gigathread 就是全局的安排block到SM的
- two warps and issue one instruction from each warp to a group of 16 CUDA cores, 16 load/store units, or 4 special function units (illustrated in Figure 3-4). The Fermi architecture, compute capability 2.x, can simultaneously handle 48 warps per SM for a total of 1,536 threads resident in a single SM at a time. 我们的这个关键就是 分组 其实有四个组合 然后选择其中一个一个作为执行选项 然后对于两个warp scheduler 就是两条流水线 然后其实每一组调度都可以看作是并行的了 不用再去管物理上的运行了上面说的48 个warp就是 同时dispatch 48 个 而不是同时运行 48个
- 64KB memory 被分成了shared memory 和L1 cache两者关系运行更改通过runtime API
- Fermi also supports concurrent kernel execution: multiple kernels launched from the same applicationtion context executing on the same GPU at the same time. Concurrent kernel execution allows programs that execute a number of small kernels to fully utilize the GPU, as illustrated in Figure 3-5. Fermi allows up to 16 kernels to be run on the device at the same time. Concurrent kernel execution makes the GPU appear more like a MIMD architecture from the programmer’s perspective.
- LD/ST 使用来进行转换地址的单元 16 个也是因为并行的原因
- kepler dynamic parallelism 允许 nested kernel invoke ; Hyper-Q 避免一个失败的kernel 调用 idle CPU 太长时间 多个task queue
- P 79 nvprof profiling driven 性能测试初步 类似linux里的一个 profile Event and metric
- memory bandwidth; compute resource ; latency
- Warps are the basic unit of execution in an SM. When you launch a grid of thread blocks, the thread blocks in the grid are distributed among SMs. 就是可以多个相同grid block在一个SM,也可以一个SM有来自不同block 最终硬件上都是一维
- warp 的划分原则 consecutive threadIdx.x !! 最后是向上取取整warps 如果非整数倍会出现空闲的不活跃thread 但是仍然会消耗占用硬件自资源也就是最终都是一维的硬件实现
- Warp Divergence 就是分支判断的问题 会 连串掩码式地执行 在优化等级较高时时间开销接近正常 解决就是 让一个分支用warp size 与运行
- 仔细想想居然很大程度上我们的这两个是独立影响的
- P89 A thread block is called an active block when compute resources, such as registers and shared memory, have been allocated to it. The warps it contains are called active warps. Active warps can be further classifi ed into the following three types: 三种 selected warp stalled warp eligible warp selected 不多于4个 是不是类似于我所说的流水线 4个选项
- block太小 可以认为与大block相比同样的共享内存能偶拥有的thread 数量较少 所有register等没有充分利用 ;太大,线程太多,没有足够的thread
Synchronization
- 两个层面 host and device 2 thread
device void __syncthreads(void) 一个让同一个block 的线程同步的函数
Configuration
配置函数 对于 blockdim 的innermost x 一般是32 的倍数 这个是有 warp 决定的 同时 一个block的thread数量不能超过 1024
通常而言 block 数量越多 并行度越高 但是load throughput会下降 但是load efficency 更高 具有更高的achieved occupancy 但是实际上 由于 block 数量的限制反而会限制active warp
第一个常见的算法就是 reduction 树形结构
有 neighbor reduction 和 interleave reduction 后者拥有更好的global memory的局部性所以性能更好
unrolling loop 同样的一个方法循环展开真的非常快 wtf 注意这里是Unrolling loop 注意 同步函数是用来进行 一个block 之间的同步的 block之间无法同步
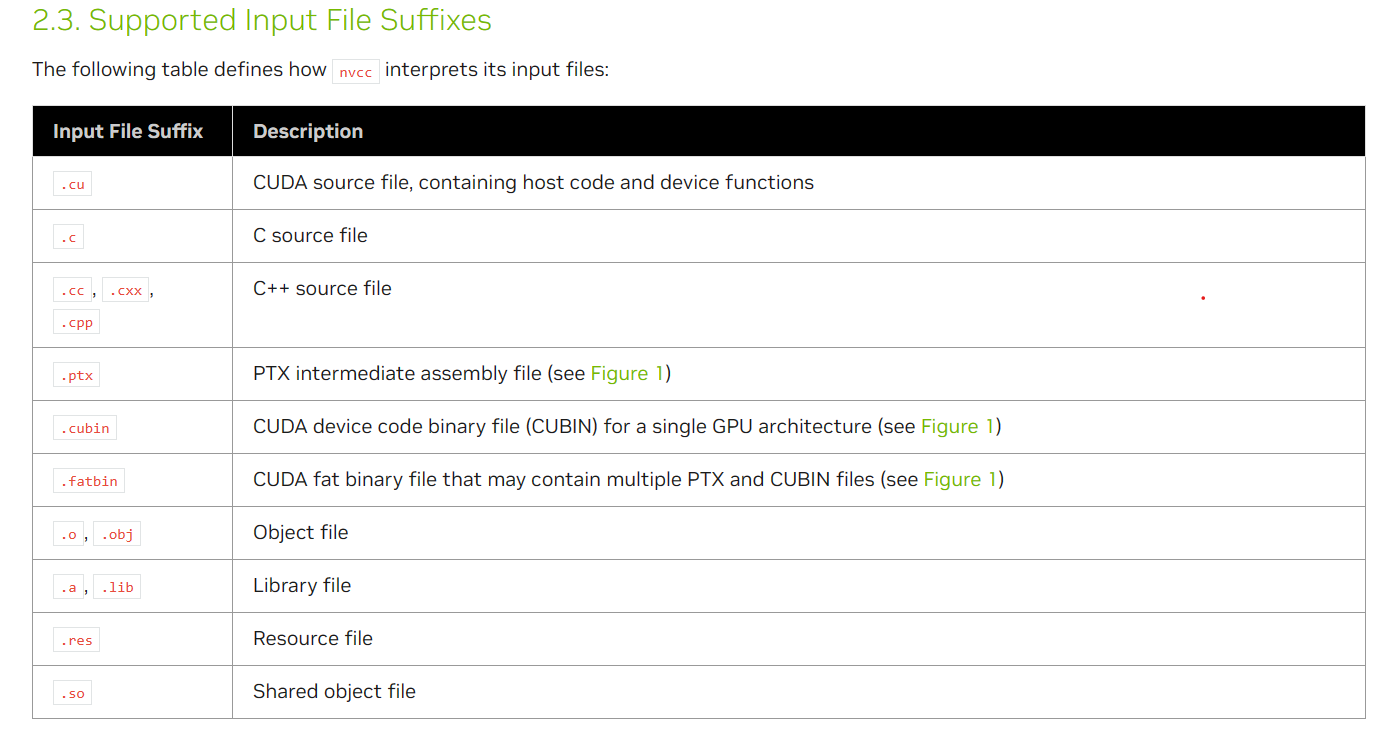 nvcc 支持的文件后缀 .c 普通的是可以编译的
nvcc 支持的文件后缀 .c 普通的是可以编译的 通常而言 grid是二维 block是三维 blockDim gridDim dim3 type 没有初始化的filed自动为1
通常而言 grid是二维 block是三维 blockDim gridDim dim3 type 没有初始化的filed自动为1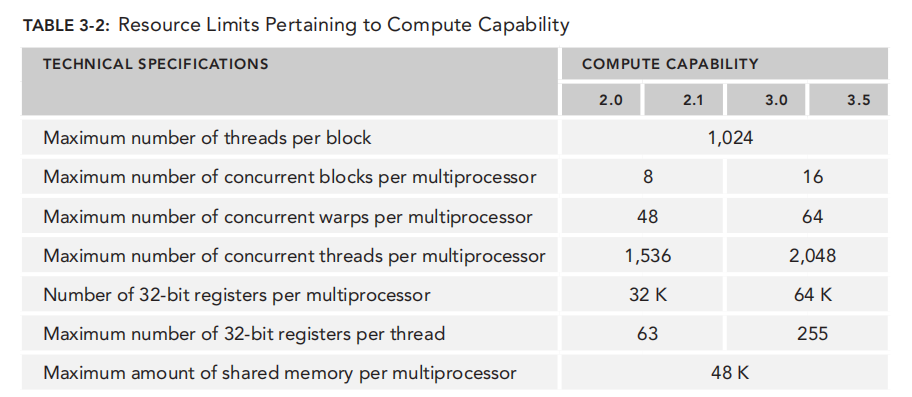
 warp 注意4 这个数字是由架构中每个SM的scheduler决定的 stall warp eligible warp 因此我们要最大化active warps
warp 注意4 这个数字是由架构中每个SM的scheduler决定的 stall warp eligible warp 因此我们要最大化active warps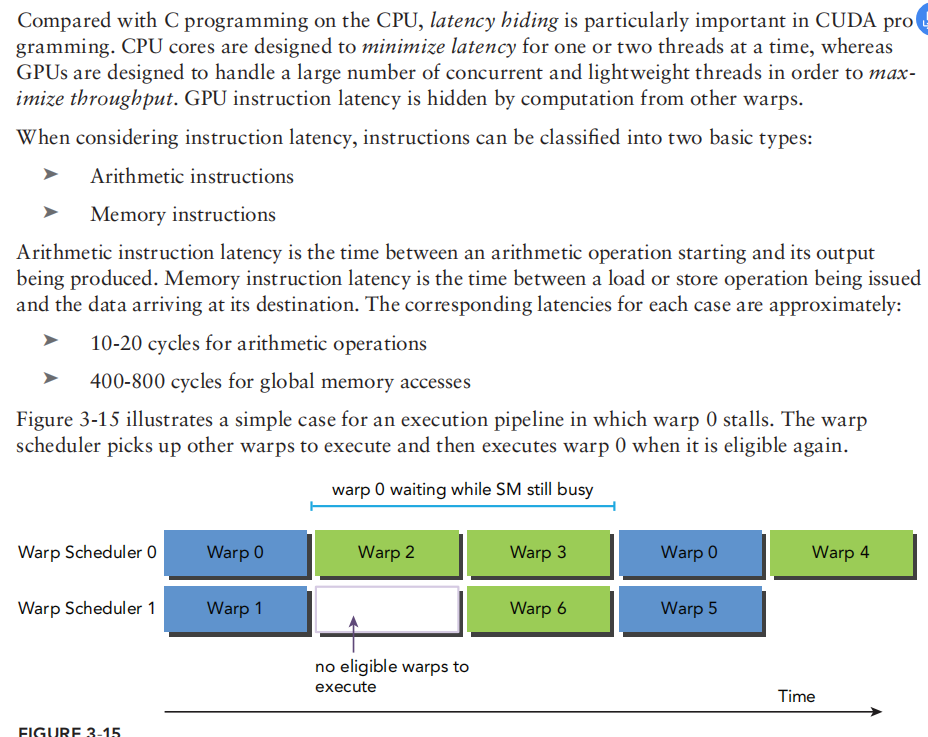 类似于CPU的调度 latency就是时间 一般用clock cycle 计算大小
类似于CPU的调度 latency就是时间 一般用clock cycle 计算大小
 太大的block size 会使每个thread硬件资源很少 太小的 block size warp 数量太少
太大的block size 会使每个thread硬件资源很少 太小的 block size warp 数量太少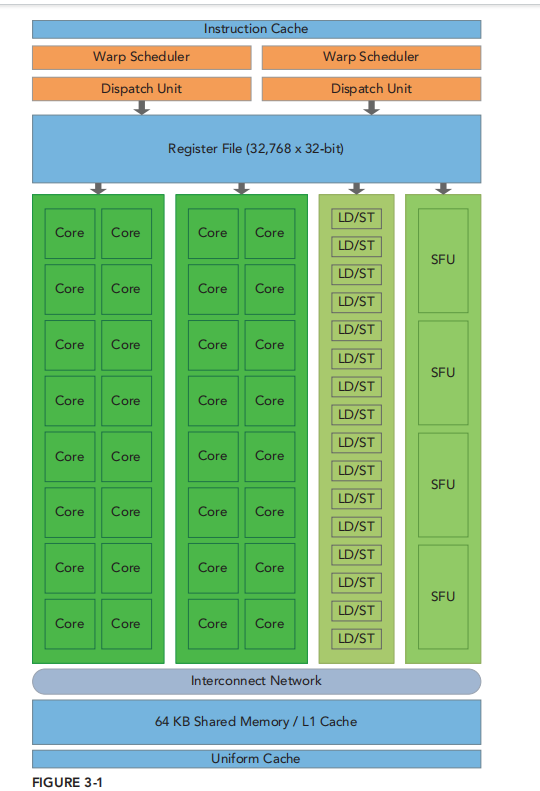
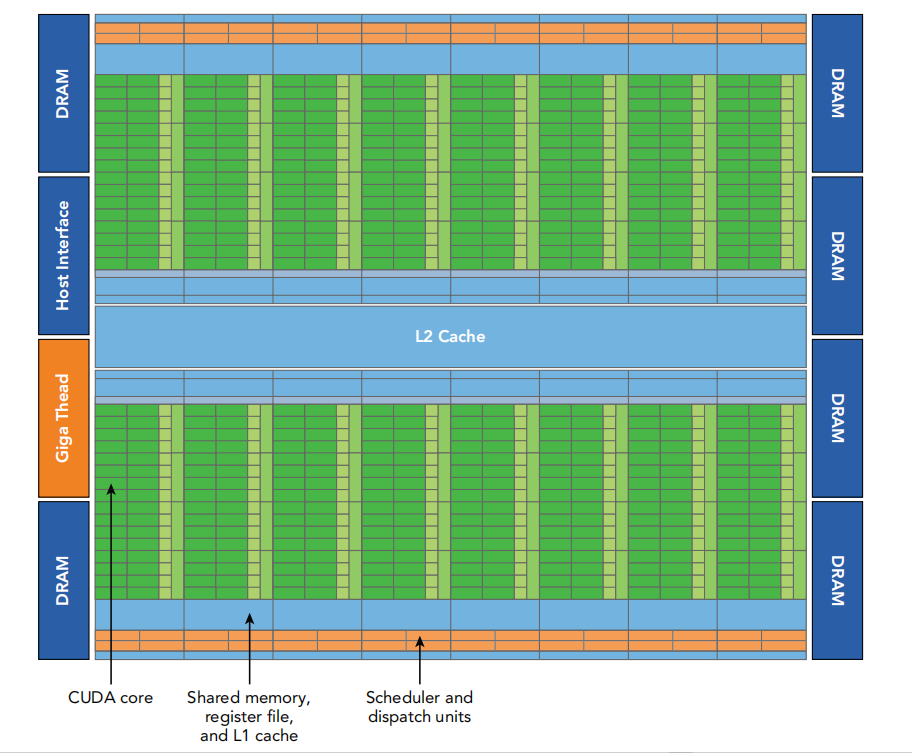 gigathread 就是全局的安排block到SM的
gigathread 就是全局的安排block到SM的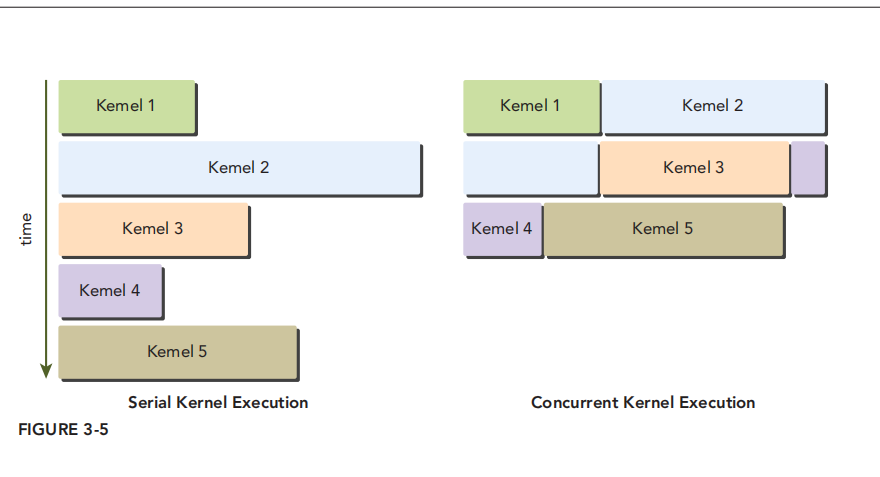
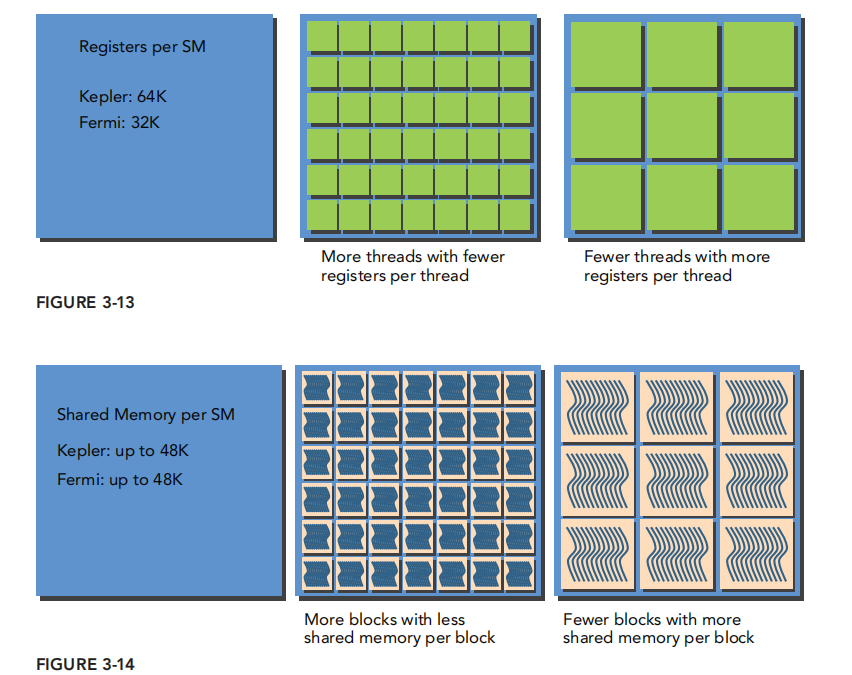 仔细想想居然很大程度上我们的这两个是独立影响的
仔细想想居然很大程度上我们的这两个是独立影响的
- Post title:CUDA
- Post author:Winter
- Create time:2023-10-24 14:20:19
- Post link:https://spikeihg.github.io/2023/10/24/CUDA/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.