


CS224N
前置知识
什么是机器学习
机器学习我的理解就是在一定条件下完成一定任务,其中任务的完成由程序本身实现。
监督学习 类似回归问题和分类问题
无监督学习类似聚类算法,没有提前的正确规则,让机器找规律
anaconda 的使用
- 原理就是 conda安装更方便 类似aptitude 可以自动帮助安装 然后就是创建虚拟环境在每个虚拟环境下安装自己的包 避免版本和包冲突
- conda create –name
- conda env list
- conda –help
- conda activate
- conda info -e
- conda deactive 退出环境
- 注意要关代理 创建环境的时候更新版本的时候也要关代理 可以设置使得能够在代理下使用但是有一点麻烦
pytorch tutorial
- tensor 的维度 创建tensor torch.empty(3,4)里面是描述tensor 的shape attribute 两个数字说明是两个dim 然后3 说明有三个行向量 4就是每个行向量有4 个元素 empty 不会进行初始化的 1 dim 就是vector 2 dim is a matrix torch.zeros(),.ones(),.rand(), 要从已有的tensor 创建拥有一样shape 的 tensor 需要用法 *_like () method 具体就是这个中括号的层数 torch 也可以直接用python 的 list 和 tuple创建甚至是混合的;在创建tensor的时候可以确定dtype,然后也看可以使用方法.to(torch.int32)
- 数学操作 内置的算术操作针对每一个元素做标量操作 对于两个tensor 也是进行的in-place 操作 但是必须要相同的shape 否则runtime error 一个特殊的例外就是broadcast 详细思考一下
- braodcast 从shape的last to first开始比较,当相等 或者其中一个为1 或者其中一个不存在都满足 直到比较完 判断时候broadcastable 然后算数的规则是用prepend 1 不玩较小维度的维度 然后对应的每个维度取最大值 注意 in-place 操作也支持broadcast
- 理解broadcast 的关键就是意识到dim=1 的时候我们可以把这个重复的地去乘
- size 就是指一个维度的元素个数 从last 开始 dim 0 dim 1 注意是从0开始的,然后对应的是shape 的第一个(3,2,1) dim=0 size=3 注意是相反的!!!!!!
- 创建tensor 的时候指明一个required_grad 这样才能够在后面调用 grad时计算此项的gradient
- 仔细研读了一下 每一个tensor 都有维护一个.grad 来存储自己的偏导数
- torch.tensor()总是拷贝tensor 要尽量避免拷贝 detach() 改变 required属性
- 卷积的filter是一个多维的matrices 一定要注意的是我们的结果始终是一个2d matrix 对于一个filter不是多个filter 妈的 kernel 就是filter 带bias 的卷积操作就是卷积的时候加上bias 得到输出 传入kernel size 是一个int默认就是方正
- dim 就是一个方向可以堆叠的方向 然后可以看括号来判断
- N batch size 自己定义一些东西 dataset 可以抽象成一个 list 每一个元素就是一个 map 例如 path: label 之类的 feature 就是我们的prediction label 就是实际值 定义dataset 和 dataloader 就是第一步 注意一张定制化的思想 很不错面向对象编程
流程
custom dataset and dataloader
dataset 抽象定义为一个map 有一个annotation file 存储所有的样本的名字 还有存储的路径 两者结合可以得到一个图片的完整路径 然后预定义transformer 三个必要的 函数 ——init—— 就是 self.img_labels read csv 读入csv 然后定义dir和 transform ——len—— ——getitem—— 对于dataloader 设置加载方式 batch shuffle 多线程加速等
layer
Linear 就是一个layer 改变输入的最内层dim 的size 由输入的参数决定 注意我们的这个layer里面已经有预先设定好的bias 和 weight 相当于就是 对于图像可能就是一个 convolve
梯度下降算法
- 同步更新所有变量
- 出发点是想要拟合一段数据 然后我们想让整个数据组的误差最小。因此我们求导。可以理解为山坡上寻找下降路线。由于公式会随着接近局部最小点而自己缩小前进距离这是一个学习。
输入是一个特征向量 的函数求偏导本质就是我们在微积分里面学习的矢量函数求导链式法则 θ的每个分量看作一个维度 然后是复合函数求导
极大似然估计
- 就是我们依照描述的事件写出这个事件发生的概率表达式,这个表达式由一个变量(涉及概率密度)决定。我们想求这个变量使得改概率函数取一个最大值。
代价函数
- 感觉与目标函数类似,一般与误差函数具有相同或者相反的单调性,然后通过一些数学技巧进行改写,以简化计算。
Batch Gradient Descent
- 这个就是传统的梯度下降,每一次前进时都要求遍历整个数据集来更新计算代价函数然后求偏导,计算量是非常巨大与难以实现的。具体原因我们会发现,偏导数求得的公式与每一个样本都有联系,例如差平方求和之类的。
Linear Algebra
- 在此再次向Pro.Strang致以最崇高的敬意。
注意点——向量拓展的梯度下降以及向量函数
注意函数变量的两个层面,一个是输入样本的维度,即样本向量的每一个维度,另一个是拟合函数中的变量即θ。h(x)(假设函数)=θ01+θ1x1 + θ2*x2+…… .eg 最后写成矩阵点积 多元线性回归
通常向量n+1 个 第0个是1为了简化表达 其余都是一个特征维度
根据上述结论重写表达式就是将θ化成对应n+1维向量然后求偏导时乘以一个xj^(i)的值。
比列失调的等高线梯度下降可能出现震荡,使用特征缩放相当于变量代换更高效将值约束在-1,1之间大约 还有归一化处理 使得平均值在0 x1-u1 代换 本质就是线性组合 u1 就是平均值 x1-u1/s u1 就是平均值 s就是标准差 就是概率论
关于学习率α 过大可能会波动或者发散 国小很慢 总之尝试不同的一系列值
多项式回归 但是我还是有问题 函数都是人提出来 没有机器自己去寻找
Normal Equation
- 线性代数永远的神,但是我已经忘记了~~~~~ 其实就是线代中的回归方程 男泵投影!!!!!
- 似乎用于线性回归,缺点:当n增大时会很慢 复杂度为3次方 而梯度下降可以正常的 大概10000为界限 例如 Word2vec 使用梯度下降法 而且只使用与线性 梯度是通法
- pinv inv pinv 进阶求逆 可以是伪逆 可是当时没看
Deep learning
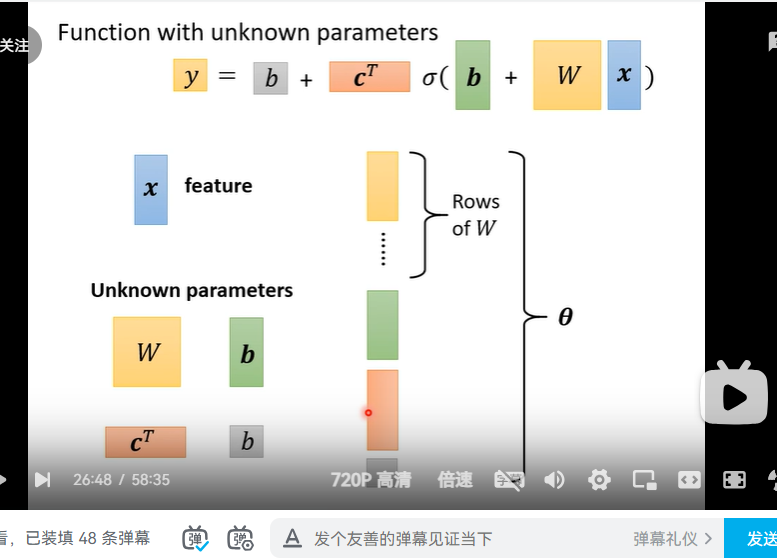
简介。机器学习就是找函数function.在台大的课中只会有梯度下降 梯度下降开始的值朴素的是随机的,但是可能存在更好的 初始值 全面的回归求解其实就是训练
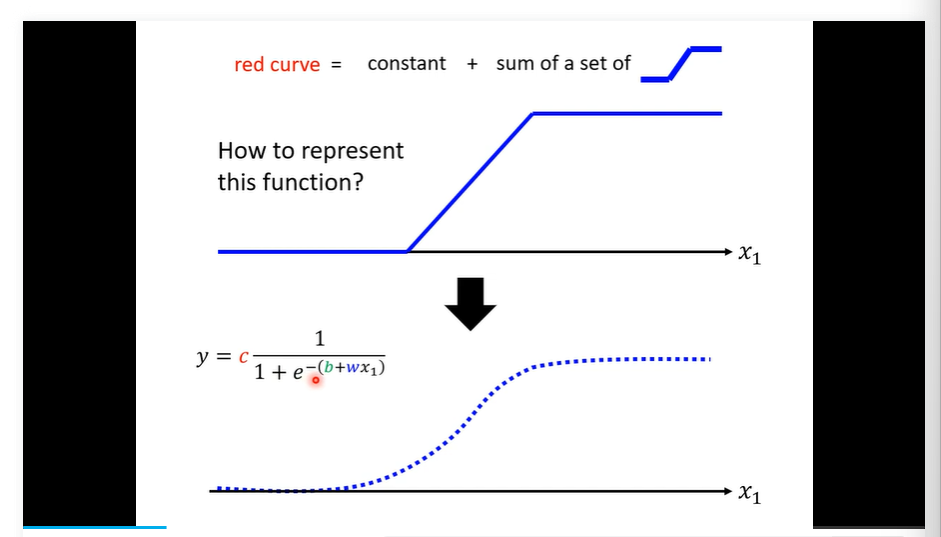
模型就是我们提出的拟合方程 课程采用的是绝对值衡量piecewise linear curve所有线性的折线都可以用一组z来拟合 同理对于光滑的 我们可以无线细分 由piecewise linear curve 来逼近 进一步又由蓝色来逼近 !!!!!!!!!!!

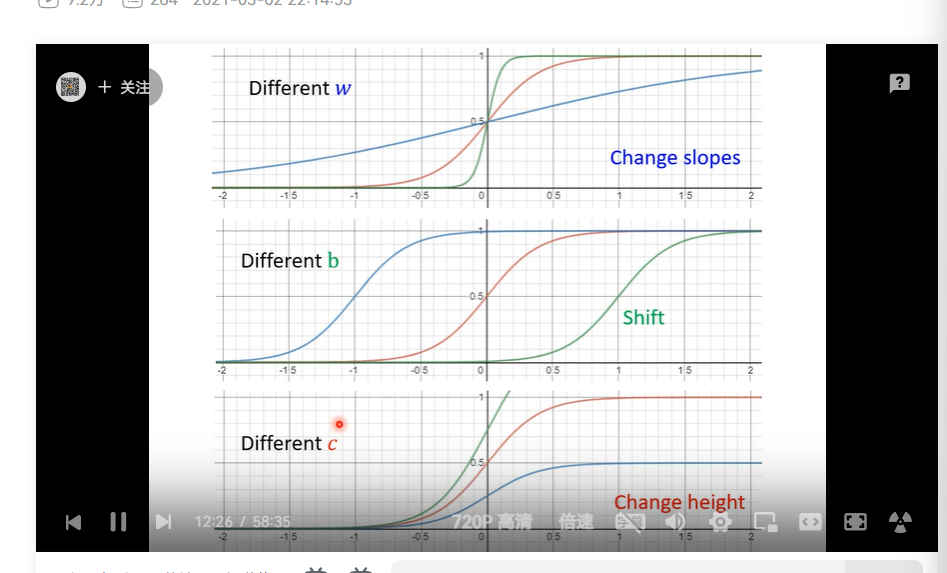
y=csigmoid(b+wx); hard sigmoid w slopes b shift
sigmoid 的个数自己决定
实际的y帽 叫做 label
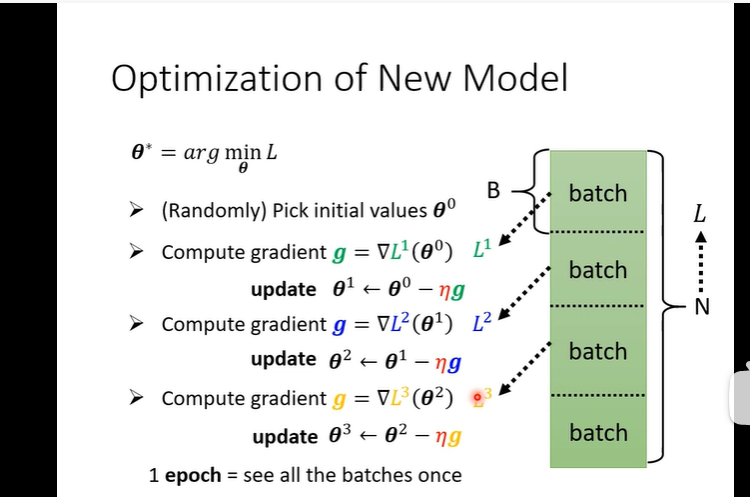
batch 将N划分作batch随机的来求梯度
epoch 是所有包都看了一遍 update就是一次更新 不一样
batch size learning rate 都是hyper parameter
ReLU rectified linear unit cmax(0,b+wx)就是hard sigmoid
就可以在所有sigmoid 使用的地方用ReLU
统称为activation function 老师都用的ReLU
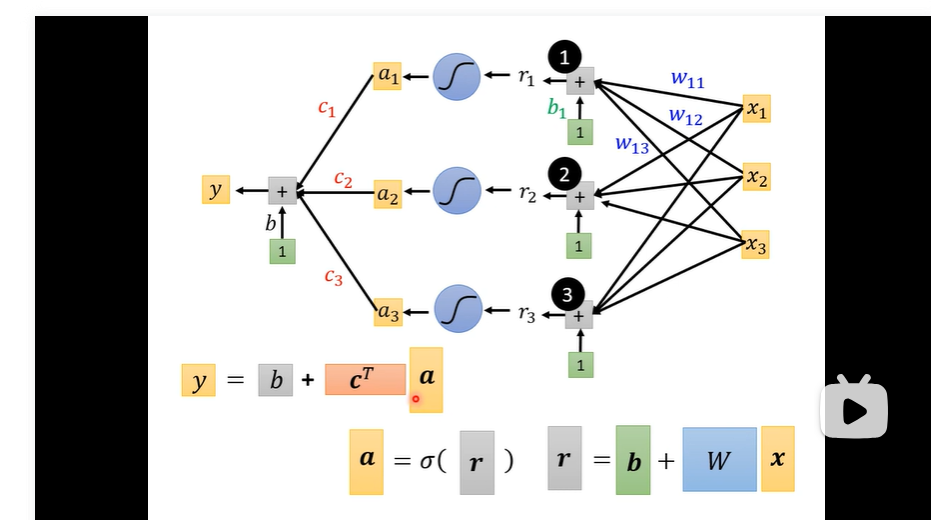
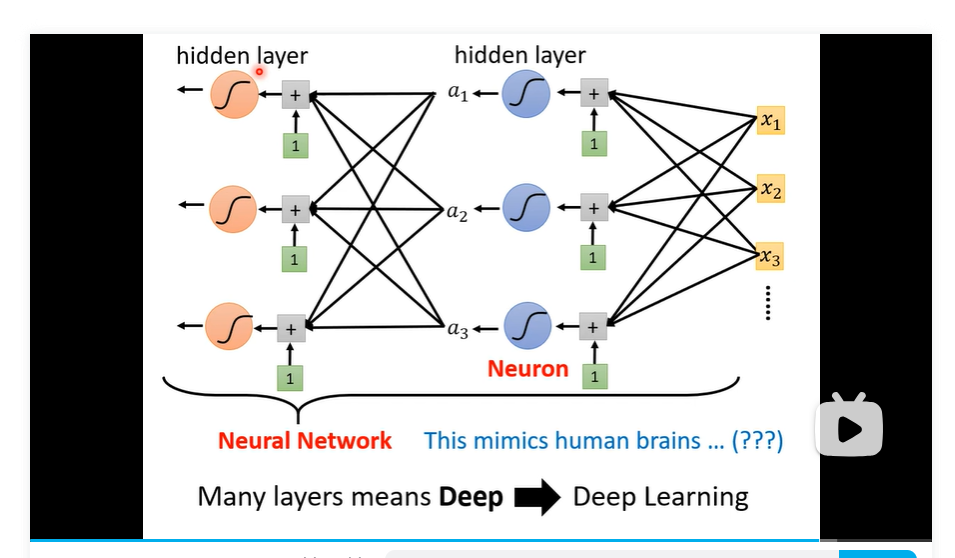
可以多层进行变换 layers 就是得到a后再带入进去
多次ReLU 意思就是
为什么更深 乐 老师太好玩了!!!!
overfitting 过拟合问题 worse on unknown data
backpropagation
anoconda 创建指令是全局的conda create 然后可以在里面下载包 用vscode 启动可以 注意激活的时候要把代理关了
jupyter notebook guide
jupyter 可以使用命令行调用
jupyter notebook 然后就进入了browserColab 使用
python code 和 shell code 其中!接shell cmd cd除外 %cd
可以选择执行的硬件 GPU runtime type 里面
ctrl+ enter 执行一个代码cell
总体而言其实就是jupyter 只不过是个互联的jupyter.
左侧的文件图标查看结构 注意下载邮寄 可以上传到google硬盘
注意自己使用的时候是在google的GPU上 所以程序结束就会消失 注意自己保存
打开新的需要在file 里面upload notebook!!!! 可以的 注意一次只能有一个session 所以需要关掉前面的 notebook maybe
真的很不错一个tesla 真棒 然后我可以试试ssh之类的然后现在发现了 ctrl+e 普通搜索很快 然后url 对url很快 因为对普通搜索会转换为我们的query 条目 然后会比较慢!!!
pytorch tensor 相当于 array 可以GPU 加速
Pytorch
- tensor就是高维数组
- 还得复习一下基本的python 语法 list dict class func 基本的一些使用 顺便复习写一写爬虫
- tensor constructor numpy zero tensor unit tensor
- 每个batch 的 loss funct 可能存在不同的差别
- sigmoid 或者 Relu 叫做 neuron 总体叫做 neural network
Python review
if var in list: if var not in list:
if var1,var2 not in list;
for key,value in dict:
for key in sorted(dict.keys()):
for value in sorted(dict.values())
answer = input(‘please enter your answer’)
int(input(‘how old are you’))
f”{var1_has_defined} {var2_has_dafined}” mesg_to_be_printed=f””
python 函数调用时候 可以直接指定 def fun(var1,var2): …… fun(var1=yes,var2=no) 但是一定要记住名字 不要出错
默认形参也是放在后面
while some_list:
item=list.pop()
do_with(item)
dict[‘new_key’]=new_value
def fun(list_para):… fun(list[:]) 传递一个切片 函数都是引用一定会修改变量的
可变形参 def func(*tuple_para): def func2(size,**dict_para):
Class in Python
class my_class(): 开头的书写方法
- def __init(self,para1,para2)__ self 必须第一个
- 然后接着是 self.para=para(实际传入实例类的形参)这样写之后this 相当于才拥有这些成员
- 普通方法 def member_func(self): 不要忘记了self
- 如果要有具有默认初始值的属性 可以直接在__init()__ 下面进行写 self.prop=1000 prop 不用出现在init括号里面
- 继承
- 首先必须括号里写明继承的类 class derived(base):
- super()._init(para,para,para)_注意里面没有self 继承全部内容
- 自己属性接着写就可以
- 可以重写父类方法 名字不同就可以
- 可以类实例作为成员 self.class_mem=classA()
这个 init 不是必须的方法 只是用来定制实例化时 类似的还有 _self_ _next_ 等用来控制 迭代器的 同时呢 生成器 generator 是一个综合了上面方法功能的函数 yield generator expression
文件操作
- with open(‘filename’) as name: 不需要close了 因为with
工具
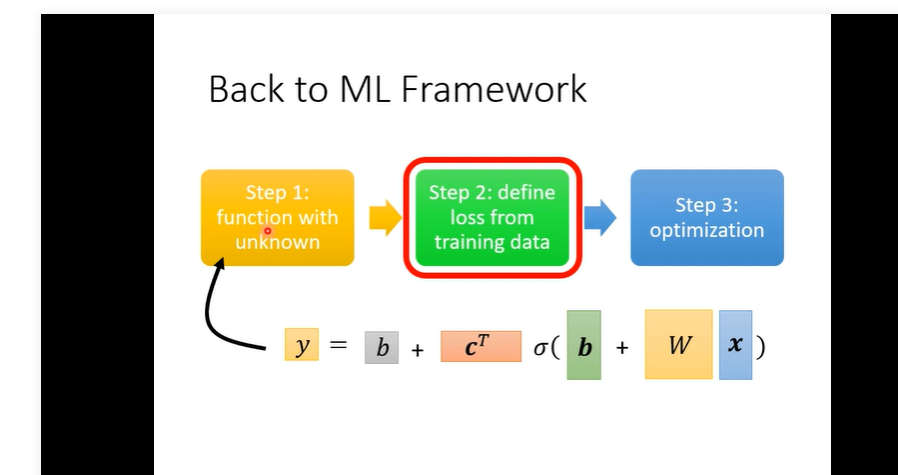
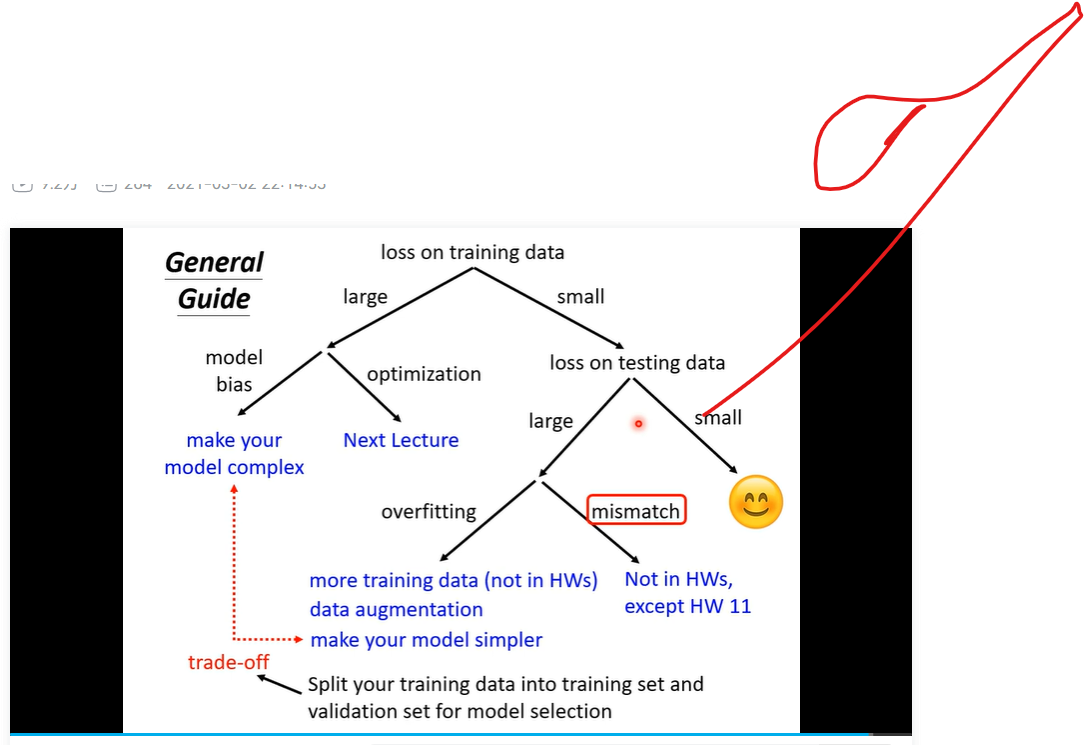
* training data 上的loss过大- Model bias 就是 我们的函数太简单 解决方法 一 增加 特征量 二 增加layer deep learning
- 优化问题 梯度下降的问题
- 怎么解决 优化的问题 next lecgt
- 一定区分 overfitting 和 优化问题 一个是test data 一个是 training data
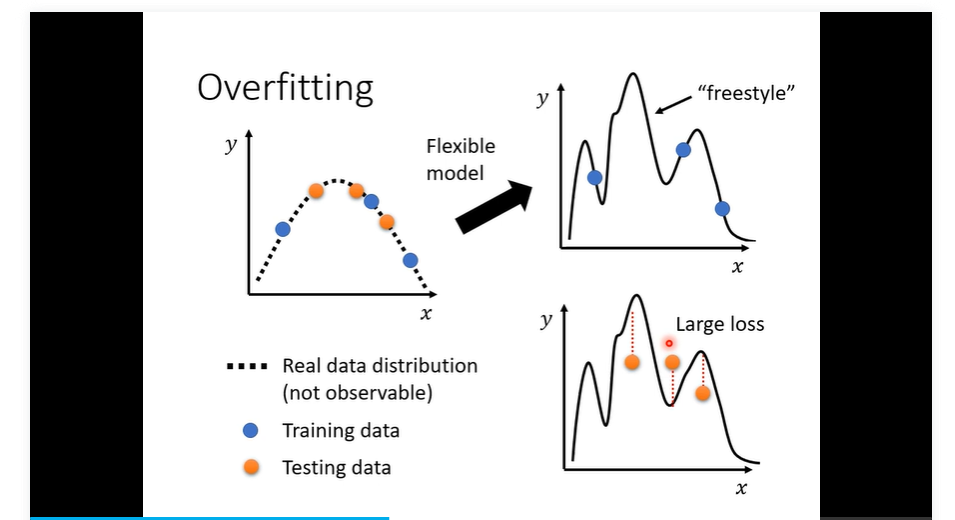
- overfitting
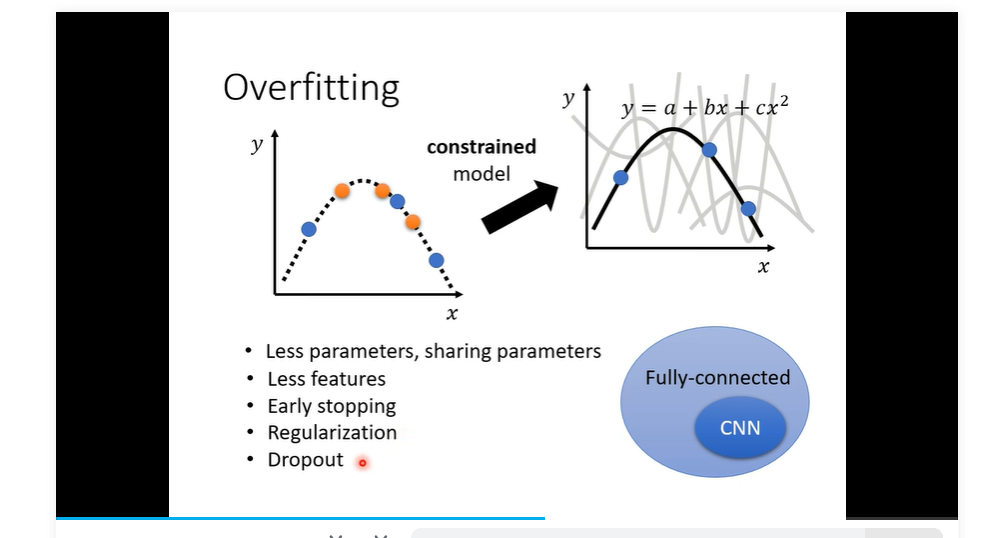
- 解决方法 增加 training data 二 data augmentation 就是自己创造一些条件 创造一些资料 需要有道理
- 减小弹性 增加限制
- full- connected比较有弹性目前我们讨论的; CNN 比较无弹性
- overfitting
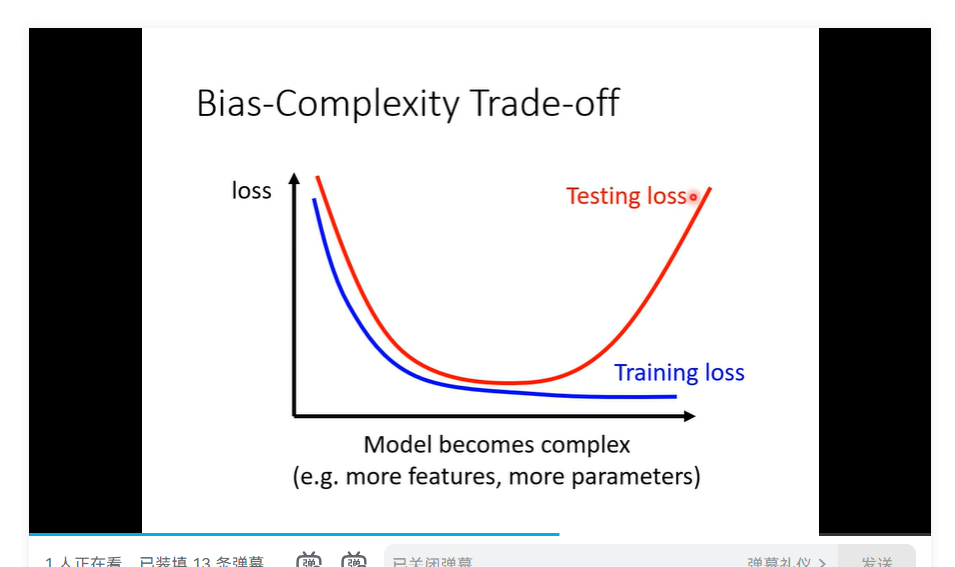
- 区分 overfitting 与 model bias 存在一个complexity 与 bias 关系
- 刚刚好的
Tips
- critical point saddle point & local minima 前者更多 通过hessian 矩阵来判断 特征值来判断 全正或者全负local其余就是saddle point
- 针对local point 的方法 batch size 一般来说越小noise 越多但实际上更好 但是在并行计算下可能更慢 第二 momentum 惯性一样的下一步加成
- learning rate 的问题 有一个方法 叫做 Adam Optimizer 就是RSM 加上 momentum 的结合 可以动态改变learning rate 。 也就是说我们的learning rate可能也是 loss stuck的原因,而非 critical point
- loss 函数也有影响 对于分类问题而言 使用最多的 是 cross entrophy 原来是用似然函数 好处就是 可以将整个surface 放得平缓
- 理解权重影响的问题 和这个surface是怎么来的 我们要不断修正的是w1 w2 mean 就是平均值 standard deviation 就是标准差 标准化 数学的影响就是 loss converge 收敛更快 但是还是有个问题,在实际的多层神经网络中 每经过一层 可能分别差别又会变大 所以我们还是需要不断地进行normalization 可以是activationfunc 之前 也可以之后 sigmoid 最好之前 因为可以化到-1 1 之间使得函数的值变化比较大 这个优化提升的是训练速度 主要是
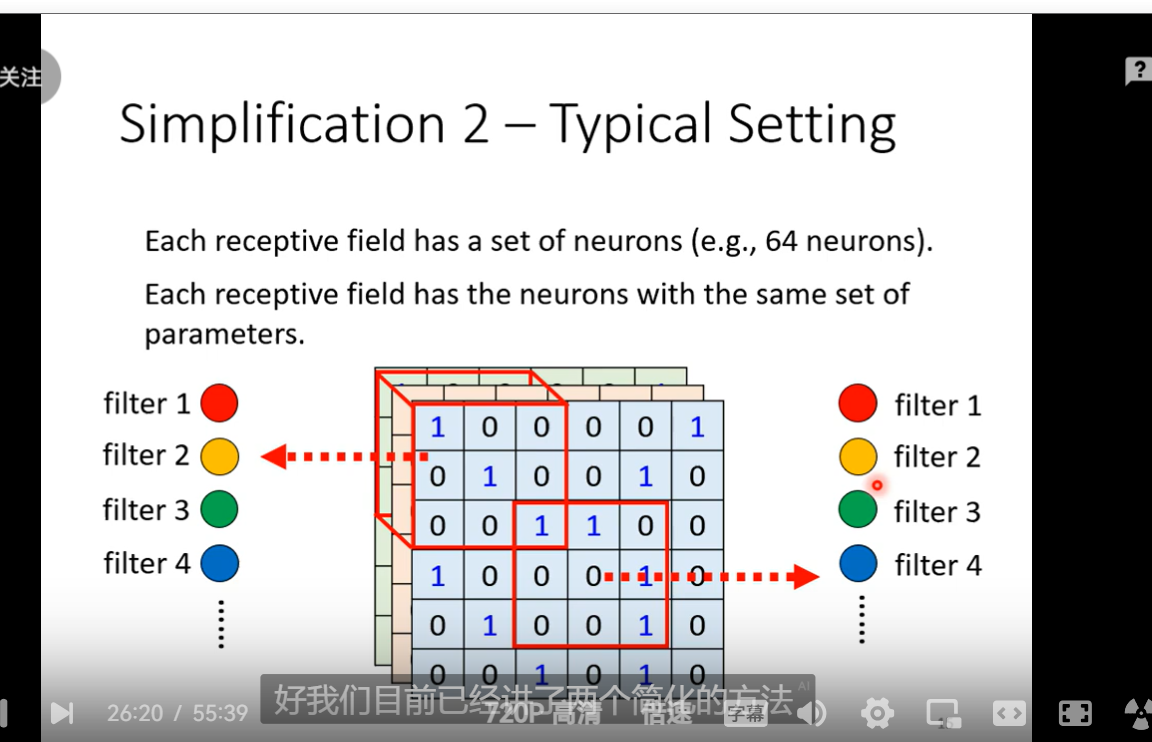
- CNN 卷积神经网影像处理,一个图像就是一个RGB的三位channel 的tensor 就是一个高维的叠加的数组 拉直就是一个向量 但是我们一般不会全部进行训练 我们会进行一定的相关的简化receptive field 这样做的一个理论 就是探查pattern 用pattern 去进行识别
- 一般通常选取都是三个channel 然后此时的长宽称为kernel size 3X3 通常就可以了 stride hyper para 超出的部分进行padding
- fully connected layer弹性最大 receptive field 共享参数 减小了弹性这两个加起来就是convolution al layer 对应的就叫 CNN model bias 较大这里的channel变成了neuron 的个数了
- pooling 方法 max pooling 的方法 为了减少运算量 现在开始减少了下面那个是flatter 还有一个重要应用 就是 playing go
- 分类问题softmax的原因简单解释 就是 我们用one-hot 向量表示我们的类 然后用1 然后我们将softmax 将其转换为-1 到 1 当然我觉得可能还是因为概率分布的问题就是越大的比例越大
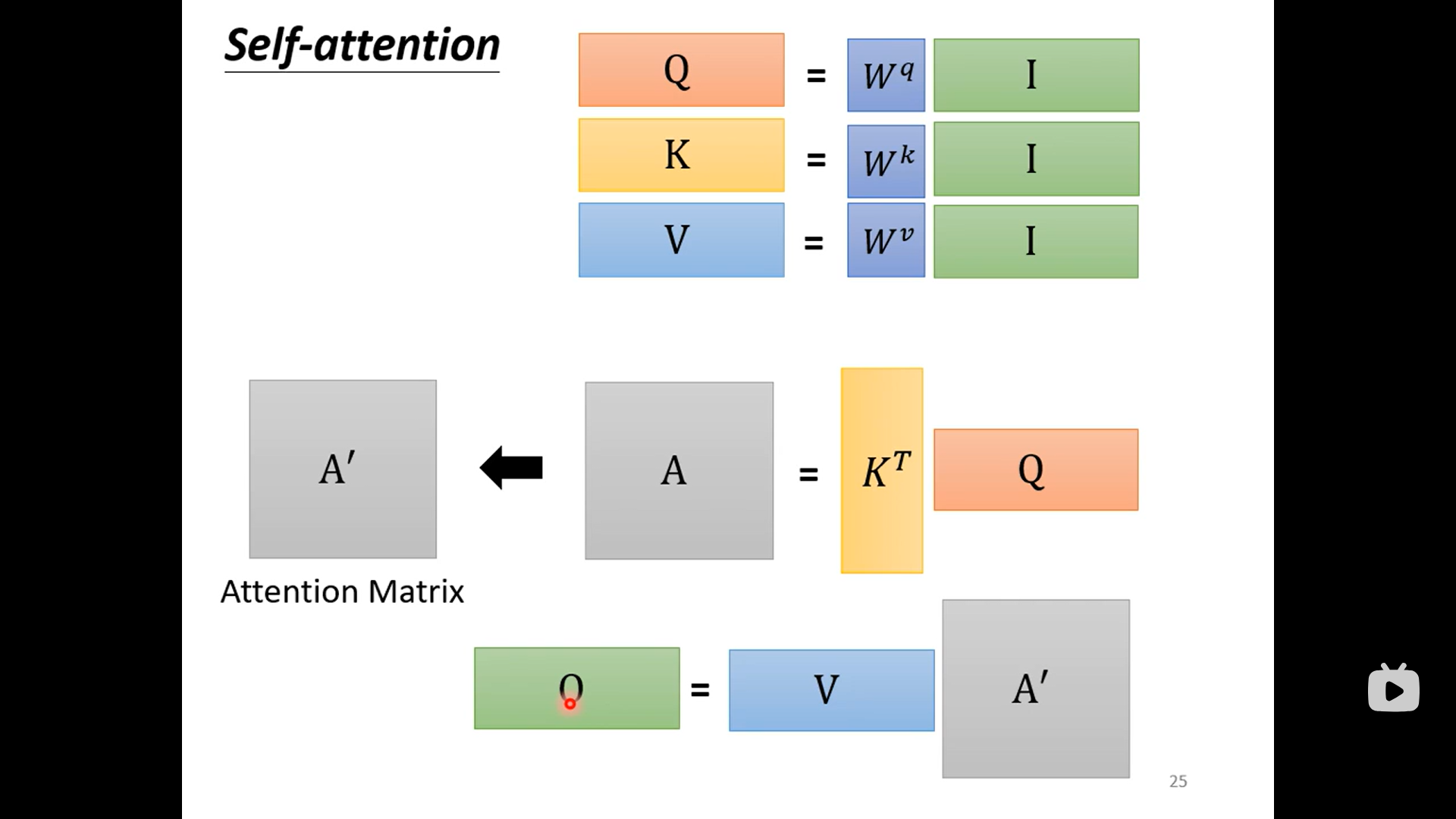
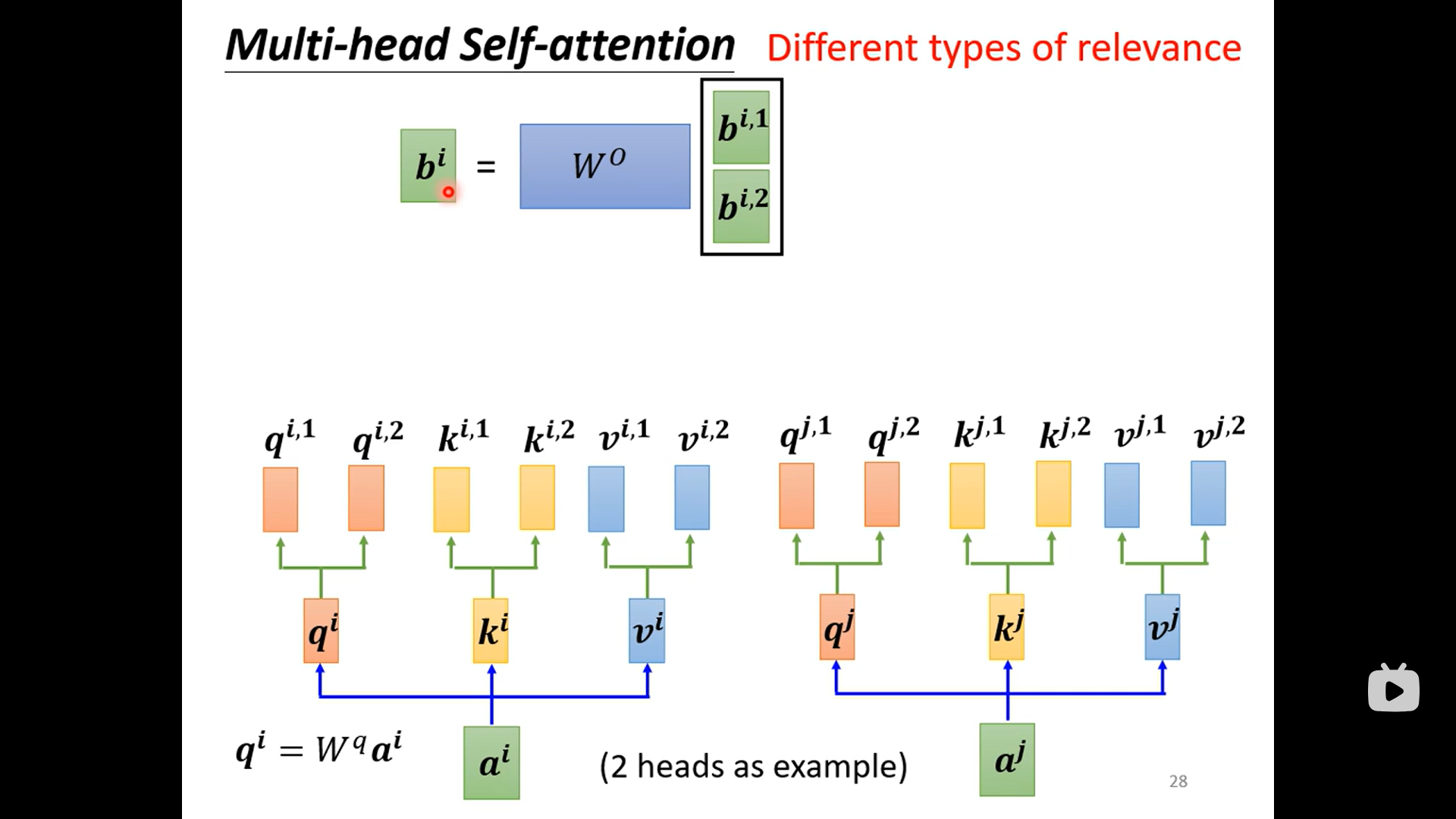
self-attention 自注意
- 问题引入 加入我们处理的input data是一个向量序列 而不是一个向量。 对应的输入也有不同的种类。比如说输入的每一个向量都计算一个label 例如判断文本每个单词的 词性 或者类似的分裂问题 。或者一个输出 比如对一句话进行定义 反正应用情形自己去想象 最复杂也许是seq2seq 输出的已是一个序列 例如翻译
- sequence labeling 如果仅仅使用前面的network 然后单独输入的话存在一个巨大的问题就是无法做到考虑上下文使用情形有限
- attention is all you need
Seq2seq
- encoder FFN feed forward network
 真的很不错一个tesla 真棒 然后我可以试试ssh之类的
真的很不错一个tesla 真棒 然后我可以试试ssh之类的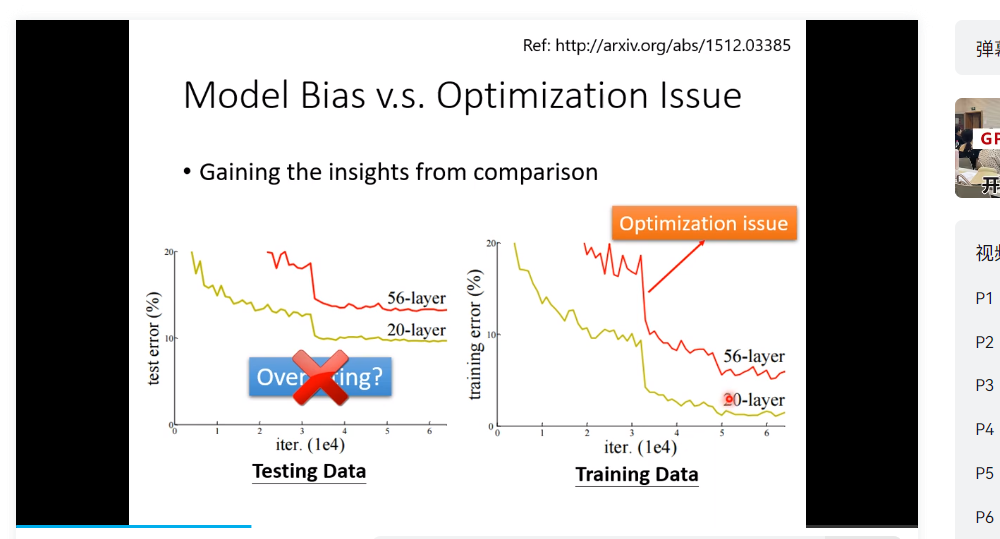
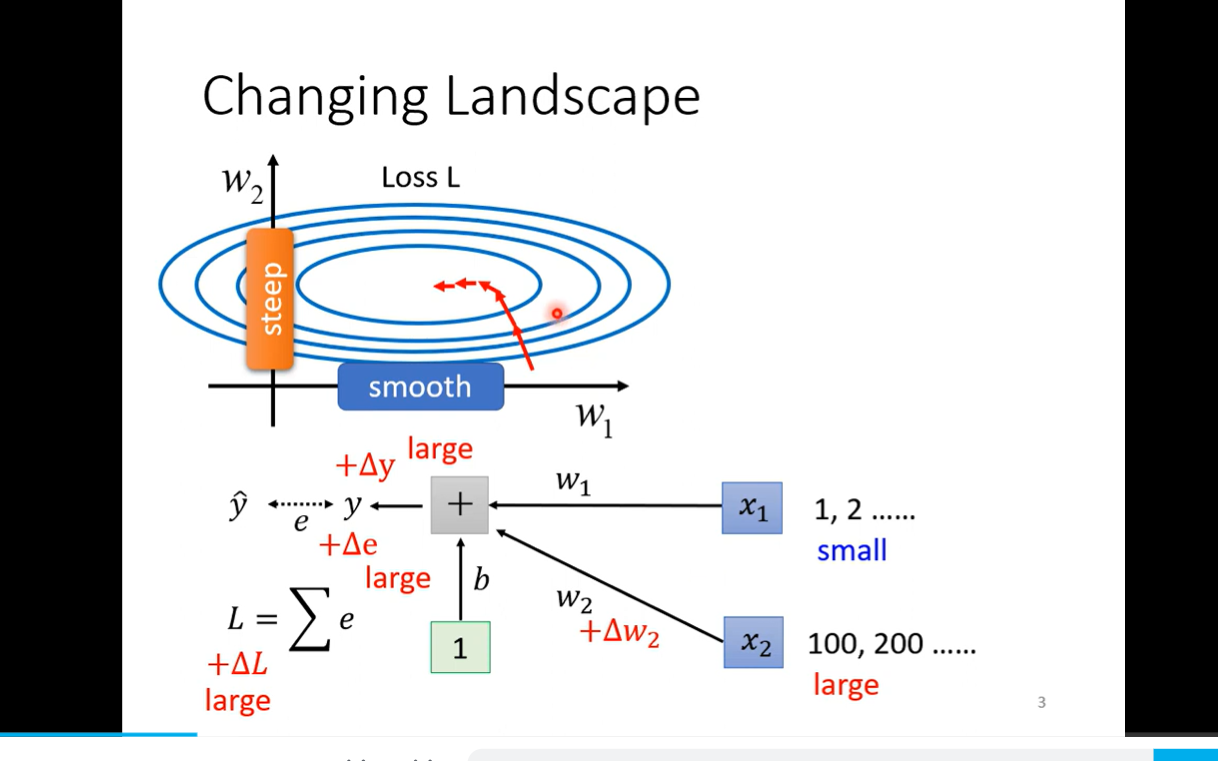 理解权重影响的问题 和这个surface是怎么来的 我们要不断修正的是w1 w2 mean 就是平均值 standard deviation 就是标准差 标准化 数学的影响就是 loss converge 收敛更快 但是还是有个问题,在实际的多层神经网络中 每经过一层 可能分别差别又会变大 所以我们还是需要不断地进行normalization 可以是activationfunc 之前 也可以之后 sigmoid 最好之前 因为可以化到-1 1 之间使得函数的值变化比较大
理解权重影响的问题 和这个surface是怎么来的 我们要不断修正的是w1 w2 mean 就是平均值 standard deviation 就是标准差 标准化 数学的影响就是 loss converge 收敛更快 但是还是有个问题,在实际的多层神经网络中 每经过一层 可能分别差别又会变大 所以我们还是需要不断地进行normalization 可以是activationfunc 之前 也可以之后 sigmoid 最好之前 因为可以化到-1 1 之间使得函数的值变化比较大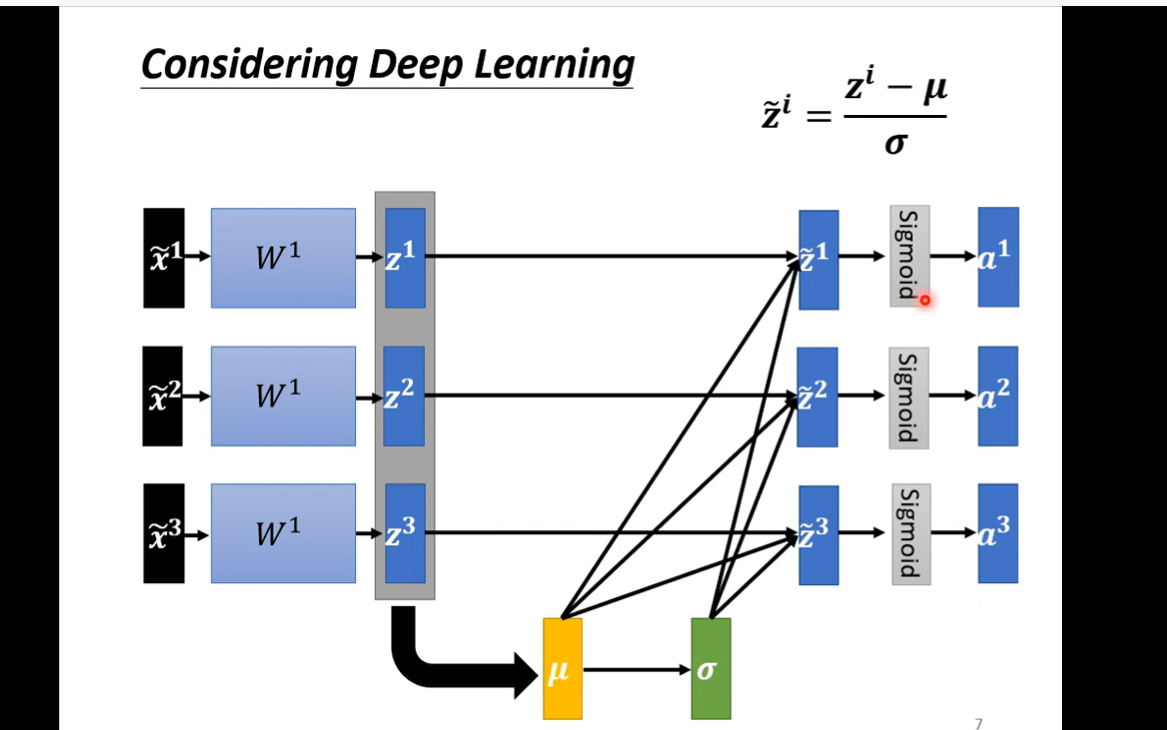 这个优化提升的是训练速度 主要是
这个优化提升的是训练速度 主要是
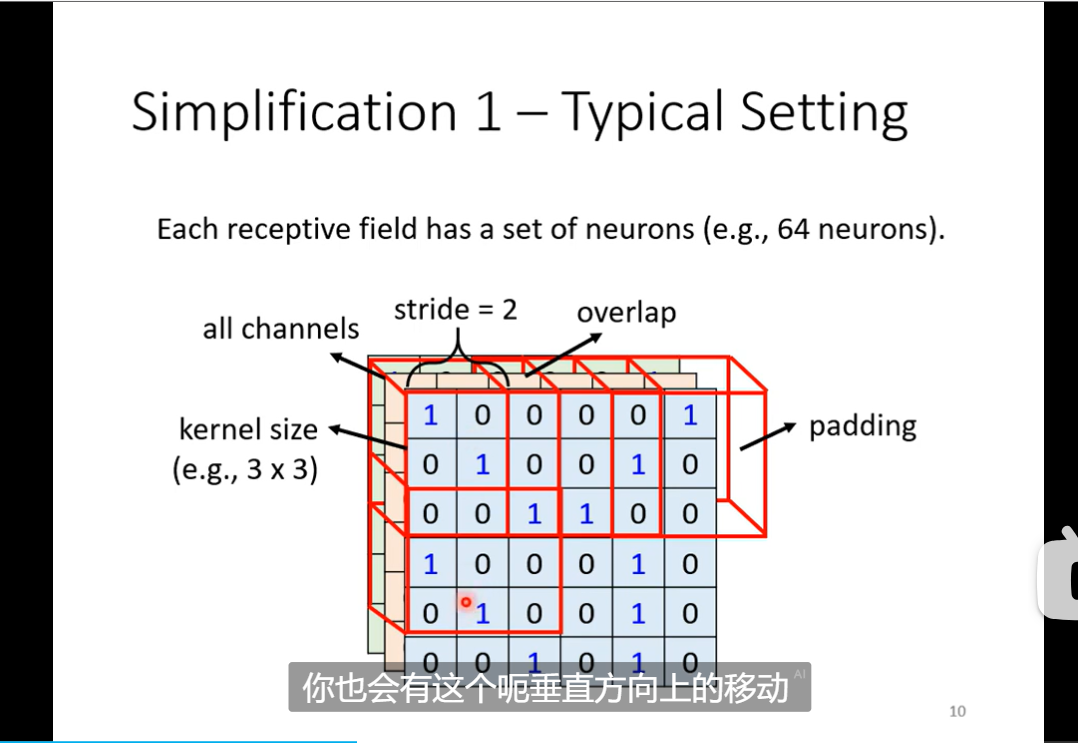
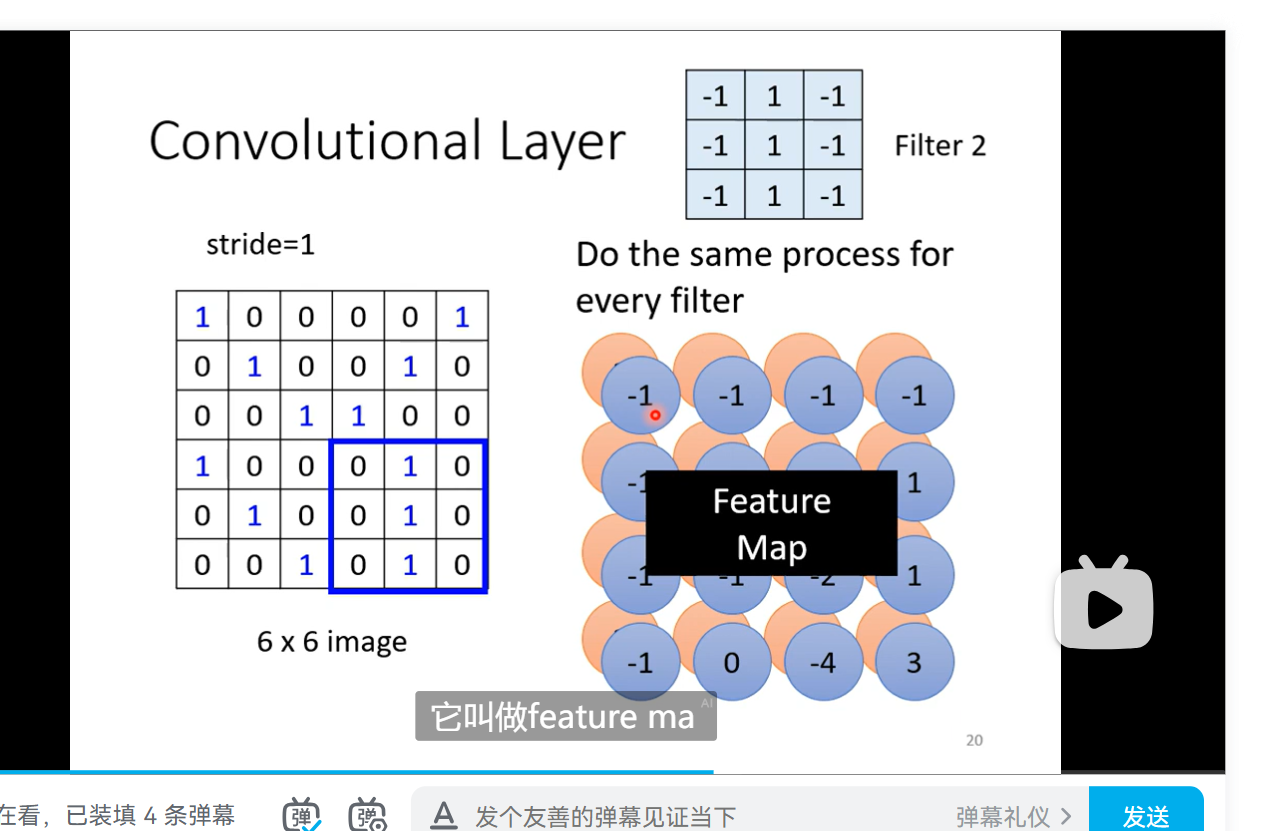 这里的channel变成了neuron 的个数了
这里的channel变成了neuron 的个数了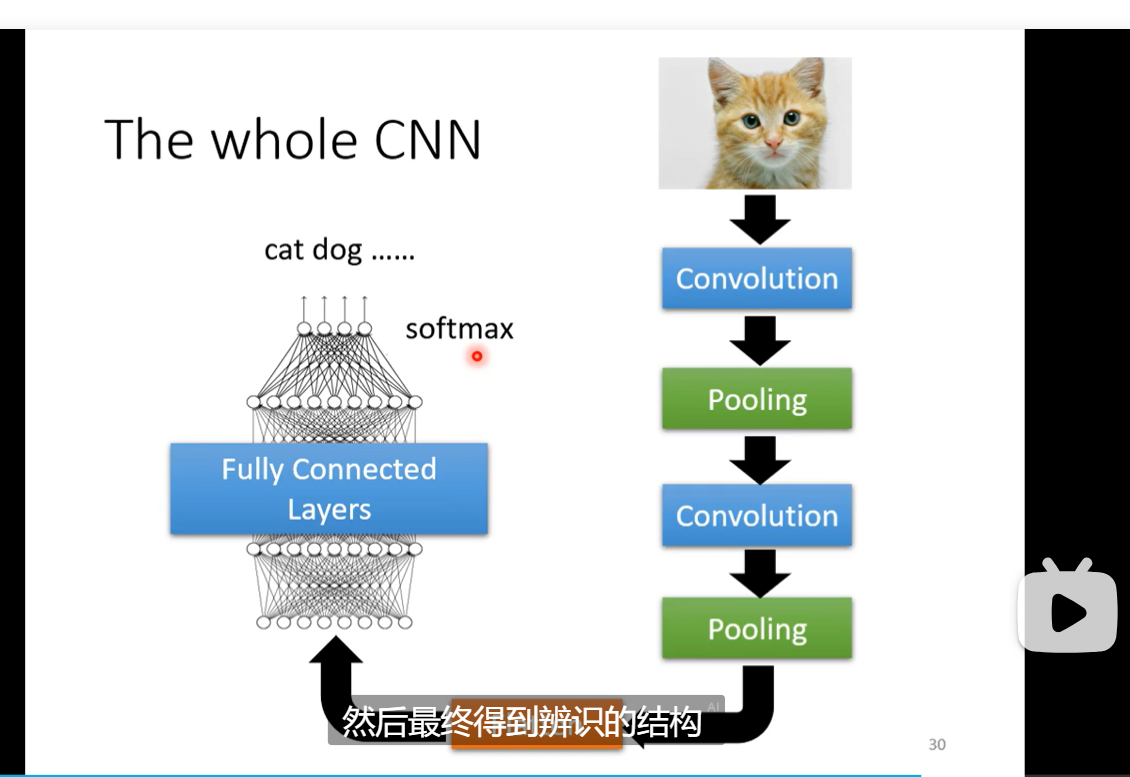 下面那个是flatter 还有一个重要应用 就是 playing go
下面那个是flatter 还有一个重要应用 就是 playing go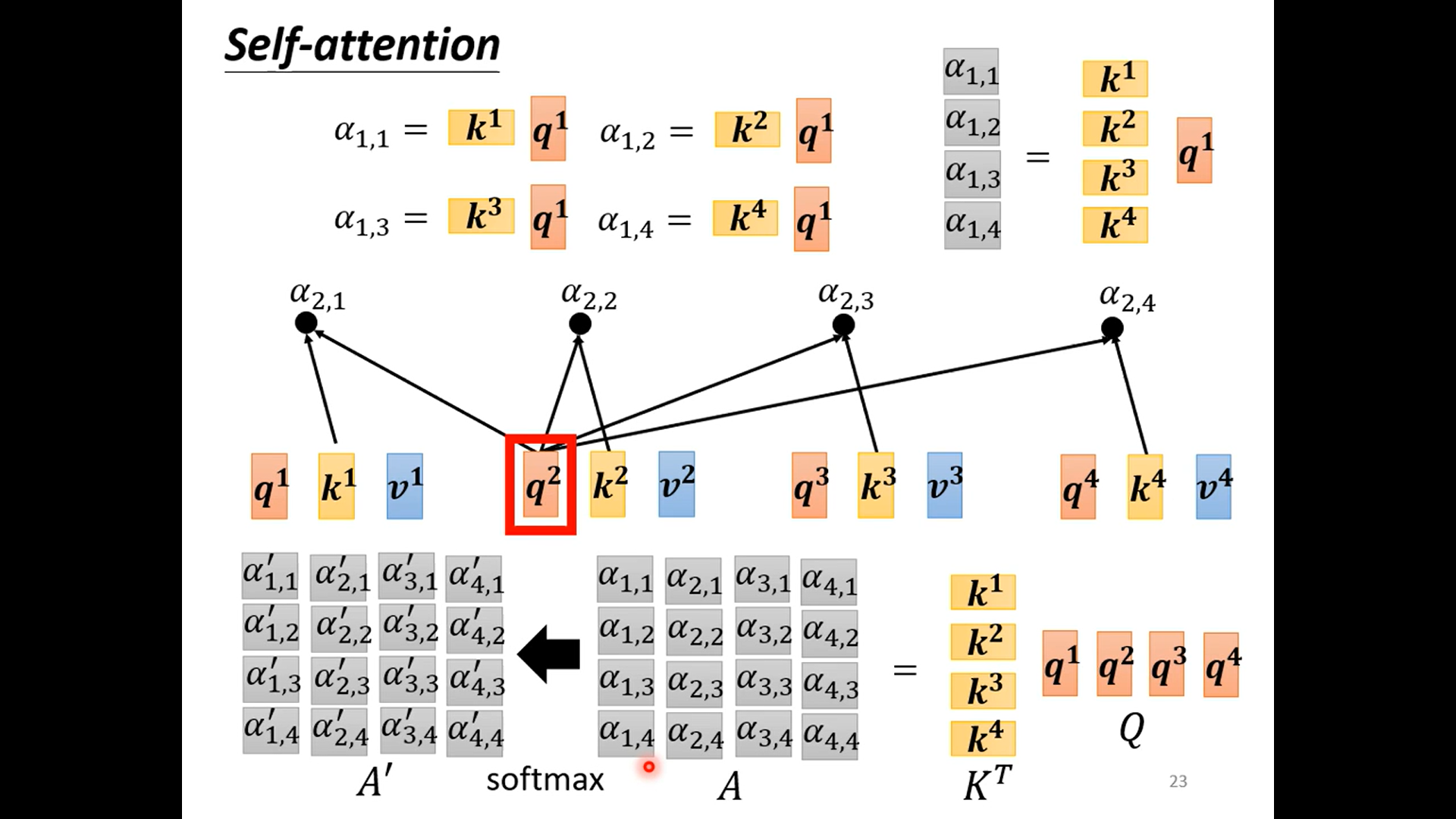
- Post title:
- Post author:Winter
- Create time:2023-10-20 14:09:31
- Post link:https://spikeihg.github.io/2023/10/20/CS224N/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.